This repository is based on https://github.com/greydanus/scribe project which was inspired by this blog post.
Download dataset from IAM Handwriting Database. There are two folders in this dataset that matter: 'ascii' and 'lineStrokes'. Put these in a './data' directory relative to this project. When an instance of this model is created for the first time it will parse all of the xml data in these files and save a processed version to a pickle file. This takes about 10 minutes but you only need to do it once.
"A project by Sam Greydanus"
 "You know nothing Jon Snow" (print)
"You know nothing Jon Snow" (print)
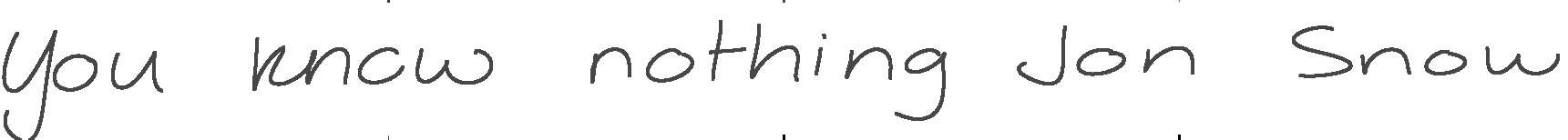 "You know nothing Jon Snow" (cursive)
"You know nothing Jon Snow" (cursive)

"lowering the bias"
 "makes the writing messier"
"makes the writing messier"
 "but more random"
"but more random"

For an easy intro to the code (along with equations and explanations) check out these Jupyter notebooks:
- install dependencies (see below).
- download the repo
- navigate to the repo in bash
- download and unzip folder containing pretrained models: https://goo.gl/qbH2uw
- place in this directory
Now you have two options:
- Run the sampler in bash:
mkdir -p ./logs/figures && python run.py --sample --tsteps 700 - Open the sample.ipynb jupyter notebook and run cell-by-cell (it includes equations and text to explain how the model works)
This model is trained on the IAM handwriting dataset and was inspired by the model described by the famous 2014 Alex Graves paper. It consists of a three-layer recurrent neural network (LSTM cells) with a Gaussian Mixture Density Network (MDN) cap on top. I have also implemented the attention mechanism from the paper which allows the network to 'focus' on character at a time in a sequence as it draws them.
The model at one time step looks like this

Unrolling in time, we get

The attention mechanism is implemented from this paper:

- All code is working with python 3.6. You will need:
- Numpy
- Matplotlib
- TensorFlow 1.4
- OPTIONAL: Jupyter (if you want to run sample.ipynb and dataloader.ipynb)