{kind=link}
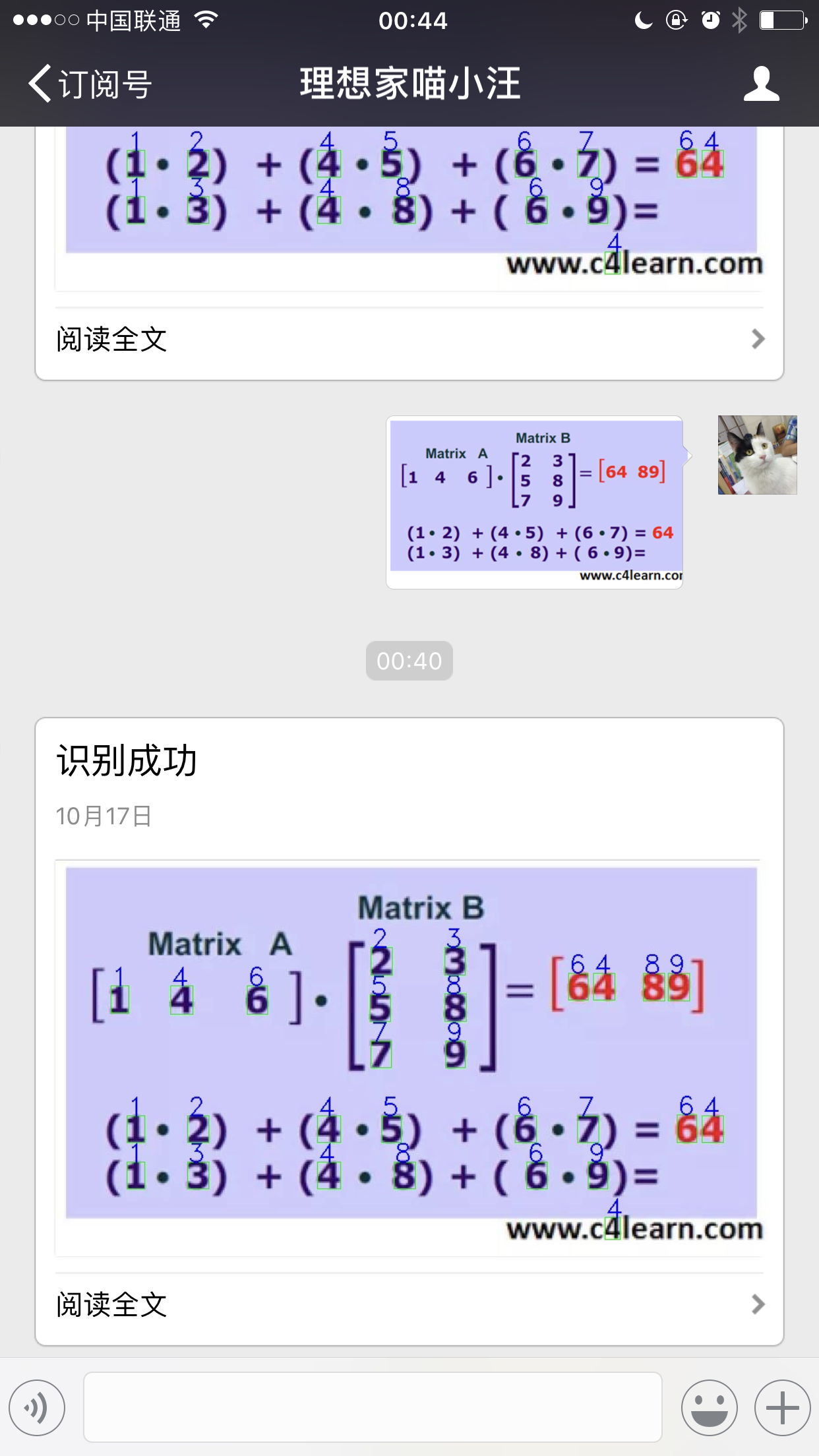
这是一个可以实现一个自动识别图片上的数字(仅支持白底黑字)的微信机器人。
个人号代码:wechat_digit_recognition.py
公众号代码:wx.py
代码:[Preprocessing dataset.ipynb](Preprocessing dataset.ipynb)
在线预览:[https://ypwhs.github.io/wechat_digit_recognition/Preprocessing dataset.html](https://ypwhs.github.io/wechat_digit_recognition/Preprocessing dataset.html)
代码:[Training Model.ipynb](Training Model.ipynb)
在线预览:[https://ypwhs.github.io/wechat_digit_recognition/Training Model.html](https://ypwhs.github.io/wechat_digit_recognition/Training Model.html)
- ItChat 1.1.11 (个人号需要)
- wechatpy 1.2.16 (公众号需要)
- requests 2.1.11 (公众号需要)
- OpenCV 3.1.0
- TensorFlow 0.10.0rc0
- Keras 1.1.0
OpenCV 建议用 brew 安装,如果你用 macOS。
brew install opencv3 --HEAD将图片转灰度,自适应二值化,提取轮廓,寻找最小矩形边界,判断是否满足预设条件,如宽、高,宽高比。

img = cv2.imread(imgpath)
gray = cv2.imread(imgpath, cv2.IMREAD_GRAYSCALE)
bw = cv2.adaptiveThreshold(gray, 255, cv2.ADAPTIVE_THRESH_GAUSSIAN_C, cv2.THRESH_BINARY_INV, 25, 25)
img2, ctrs, hier = cv2.findContours(bw.copy(), cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
rects = [cv2.boundingRect(ctr) for ctr in ctrs]
for rect in rects:
x, y, w, h = rect
roi = gray[y:y + h, x:x + w]
hw = float(h) / w
if (w < 200) & (h < 200) & (h > 10) & (w > 10) & (1.1 < hw) & (hw < 5):
res = resize(roi)
...将满足条件的图片缩放至最大边长为28的小图,然后将其放入一个28*28的白色图像的中心位置。这样做的原因是神经网络只接受28*28的数据。
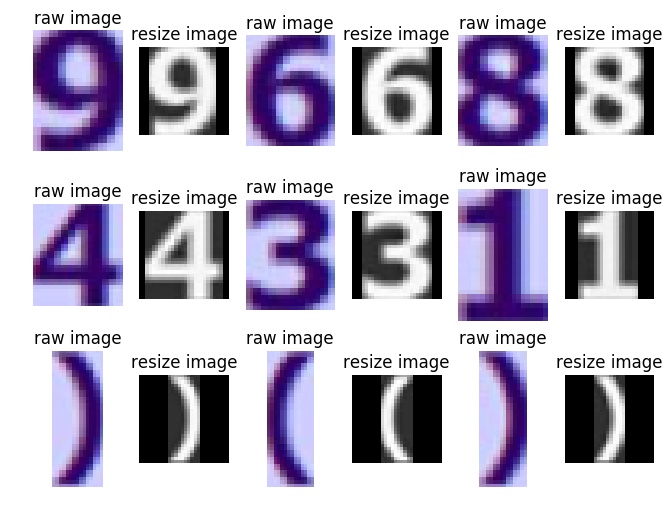
def resize(rawimg):
fx = 28.0 / rawimg.shape[0]
fy = 28.0 / rawimg.shape[1]
fx = fy = min(fx, fy)
img = cv2.resize(rawimg, None, fx=fx, fy=fy, interpolation=cv2.INTER_CUBIC)
outimg = np.ones((28, 28), dtype=np.uint8) * 255
w = img.shape[1]
h = img.shape[0]
x = (28 - w) / 2
y = (28 - h) / 2
outimg[y:y+h, x:x+w] = img
return outimg将处理好的图片送入深度神经网络中运算,得到识别的结果。11类是因为0~9代表各个数字,10代表非数字。

网络结构如下: 784->512->512->11
____________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
====================================================================================================
dense_1 (Dense) (None, 512) 401920 dense_input_1[0][0]
____________________________________________________________________________________________________
activation_1 (Activation) (None, 512) 0 dense_1[0][0]
____________________________________________________________________________________________________
dropout_1 (Dropout) (None, 512) 0 activation_1[0][0]
____________________________________________________________________________________________________
dense_2 (Dense) (None, 512) 262656 dropout_1[0][0]
____________________________________________________________________________________________________
activation_2 (Activation) (None, 512) 0 dense_2[0][0]
____________________________________________________________________________________________________
dropout_2 (Dropout) (None, 512) 0 activation_2[0][0]
____________________________________________________________________________________________________
dense_3 (Dense) (None, 11) 5643 dropout_2[0][0]
____________________________________________________________________________________________________
activation_3 (Activation) (None, 11) 0 dense_3[0][0]
====================================================================================================
Total params: 670219
____________________________________________________________________________________________________
识别出来以后用方框标记出来,然后将识别好的数字打印在图上。
if (w < 200) & (h < 200) & (h > 10) & (w > 10) & (1.1 < hw) & (hw < 5):
res = resize(roi)
res = cv2.bitwise_not(res)
res = np.resize(res, (1, 784))
predictions = model.predict(res)
predictions = np.argmax(predictions)
if predictions != 10:
cv2.rectangle(img, (x, y), (x+w, y+h), (0, 255, 0), 1)
cv2.putText(img, '{:.0f}'.format(predictions), (x, y), cv2.FONT_HERSHEY_DUPLEX, h/25.0, (255, 0, 0))收到任何人发过来的图片以后,程序自动下载图片,然后识别,保存标记识别好的数字的图片,发送给刚才发图片的人。
@itchat.msg_register([PICTURE])
def download_files(msg):
friend = itchat.search_friends(userName=msg['FromUserName'])
print time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()), friend['NickName'], msg['Type']
filename = msg['FileName']
convertfilename = filename.replace('.', '.convert.')
msg['Text'](filename) # download image
if cv2.imread(filename) is not None:
cv2.imwrite(convertfilename, convert(filename))
itchat.send('@img@%s' % convertfilename, msg['FromUserName'])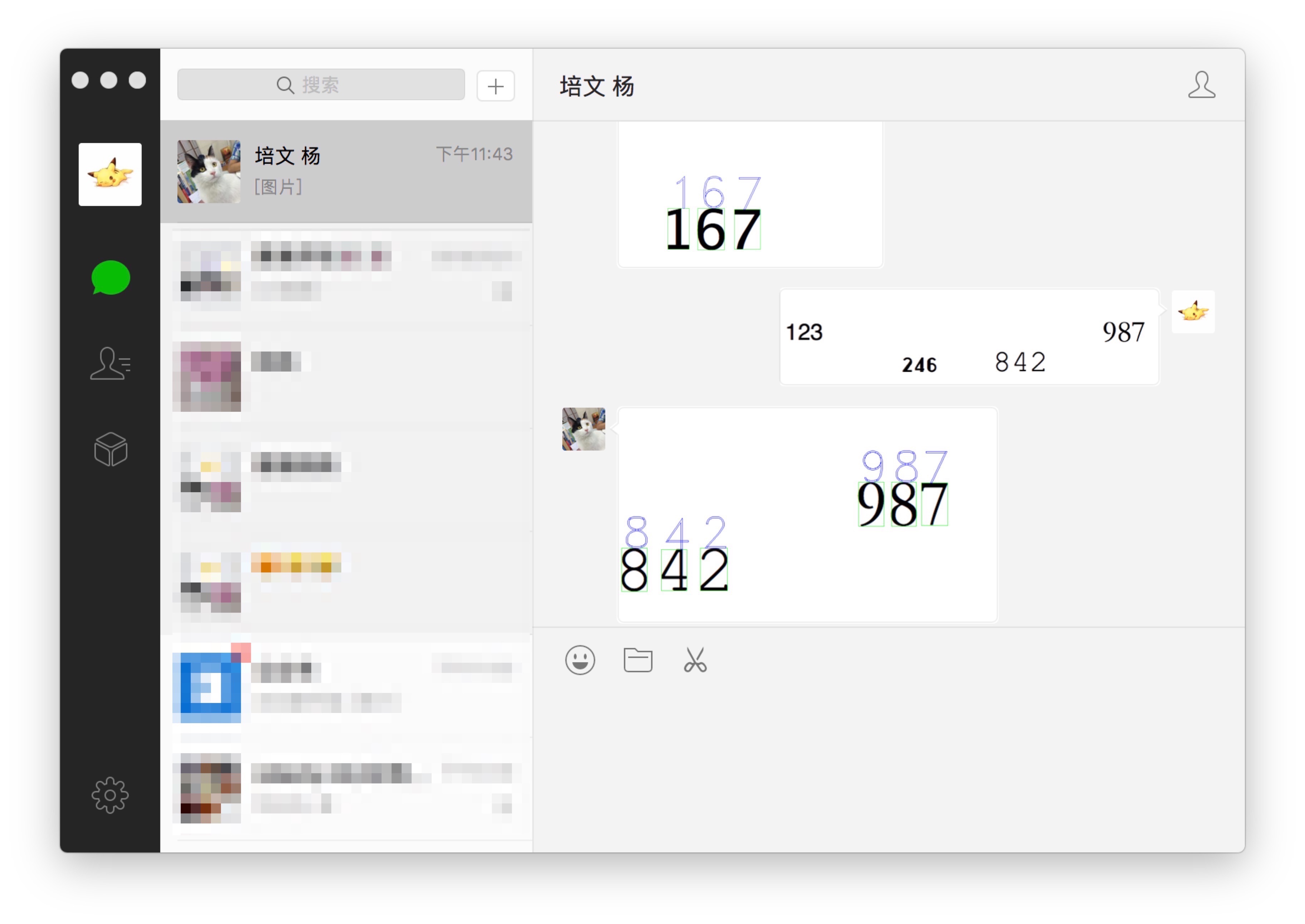
首先需要配置 apache 支持 python cgi 应用,然后在公众号后台配置服务器,得到 token 和 EncodingAESKey。当有人发送消息时,会自动将消息 POST 到预设的地址(比如:http://w.luckiestcat.com/wx.py),我们通过一系列代码下载图片,然后识别保存识别后的图片到服务器上,然后发送给刚才发图片的人。
msg = parse_message(body_text)
reply = ''
if msg.type == 'text':
reply = create_reply('Text:' + msg.content.encode('utf-8'), message=msg)
elif msg.type == 'image':
reply = create_reply('图片', message=msg)
try:
r = requests.get(msg.image) # download image
filename = 'img/' + str(int(time.time())) + '.jpg';
convertfilename = filename.replace('.', '.convert.')
with open(filename, 'w') as f:
f.write(r.content)
if cv2.imread(filename) is not None:
# load model
with open('model.json', 'r') as f:
model = model_from_json(f.read())
model.load_weights('model.h5')
cv2.imwrite(convertfilename, convert(filename))
url = 'http://w.luckiestcat.com/' + convertfilename
reply = ArticlesReply(message=msg, articles=[{
'title': u'识别成功',
'url': url,
'description': u'',
'image': url
}])
except:
reply = create_reply('识别失败', message=msg)
print reply