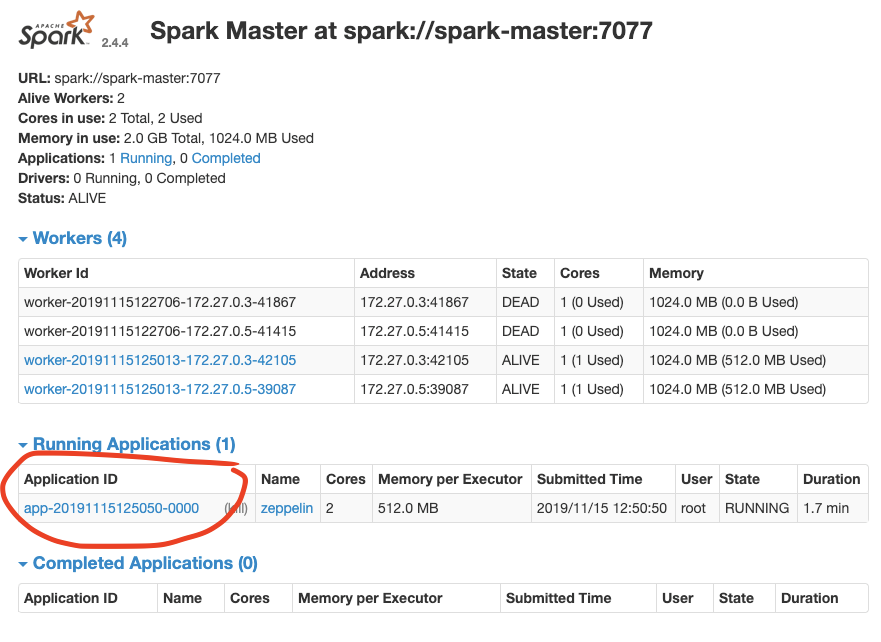
AWS LocalStack + Spark Cluster + Zeppelin using Docker
This stack can be deployed into any local development environment which runs docker. It provides a way to develop analytic jobs (Lambda/Glue/EMR etc.) offline avoiding incuring costs on AWS by mocking AWS resources LocalStack.
- Install Docker for Desktop
- Windows Users:
make install
LocalStack Home Dashboard: http://localhost:8055/#!/infra
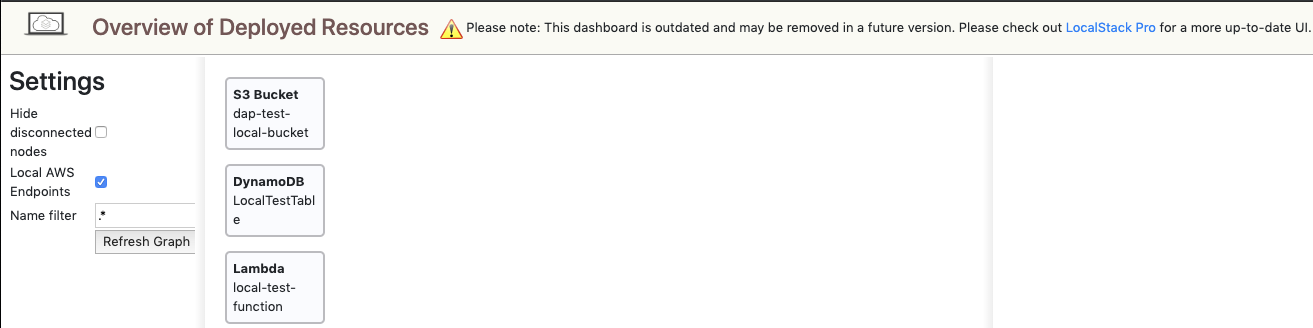
Resources used in this example:
- S3 http://localhost:4572
- DynamoDB http://localhost:4569
- Lambda http://localhost:4574
- Creating a test bucket and uploading a text file.
aws --endpoint-url=http://localhost:4572 s3 mb s3://dap-test-local-bucket
aws --endpoint-url=http://localhost:4572 s3 cp localstack/test-s3-file.txt s3://dap-test-local-bucket/- You can use Python Boto3 client to check the contents in a bucket.
import boto3
s3_conn = boto3.client('s3', endpoint_url='http://localhost:4572')
objects = s3_conn.list_objects_v2(Bucket='dap-test-local-bucket')['Contents']
objects
[{'Key': 'test-s3-file.txt', 'LastModified': datetime.datetime(2019, 11, 14, 13, 52, 54, 713000, tzinfo=tzutc()), 'ETag': '"39a870a194a787550b6b5d1f49629236"', 'Size': 10, 'StorageClass': 'STANDARD'}]- Check the test lambda function
localstack/lambda_function.py
import boto3
import logging
from datetime import datetime
LOGGER = logging.getLogger()
LOGGER.setLevel(logging.INFO)
S3_CLIENT = boto3.client('s3', endpoint_url='http://localhost:4572')
def handler(event, context):
LOGGER.info('I\'m putting something in S3')
test_object_key = 'a-object-{0}'.format(datetime.now().isoformat())
S3_CLIENT.put_object(
Bucket='dap-test-local-bucket',
Key=test_object_key,
Body='some body'
)
return {
"message": "{0} placed into S3".format(test_object_key)
}- Register lambda function to AWS (LocalStack)
zip lambda_function.zip lambda_function.py
aws --endpoint-url=http://localhost:4574 lambda create-function \
--region eu-west-2 \
--function-name local-test-function \
--runtime python3.7 \
--handler lambda_function.handler \
--memory-size 128 \
--zip-file fileb://localstack/lambda_function.zip \
--role arn:aws:iam::123456:role/notavailable- Invoke Lambda function to test
aws --endpoint-url=http://localhost:4574 lambda invoke --function-name local-test-function out --log-type Tail
- Create Table
aws --endpoint-url=http://localhost:4569 dynamodb create-table \
--table-name LocalTestTable \
--attribute-definitions \
AttributeName=Name,AttributeType=S AttributeName=Desciption,AttributeType=S \
--key-schema AttributeName=Name,KeyType=HASH AttributeName=Desciption,KeyType=RANGE \
--provisioned-throughput ReadCapacityUnits=1,WriteCapacityUnits=1
aws --endpoint-url=http://localhost:4569 dynamodb put-item \
--table-name LocalTestTable \
--item '{
"Name": {"S": "nilan3"},
"Description": {"S": "Nilan Balachandran"} ,
"Role": {"S": "Owner"} }' \
--return-consumed-capacity TOTAL- Query table
aws --endpoint-url=http://localhost:4569 dynamodb scan --table-name LocalTestTableLocal testing using a Spark standalone cluster and storing dummy data in LocalStack S3 to read from.
Access Zeppelin notebook and run Spark code (http://localhost:7000)
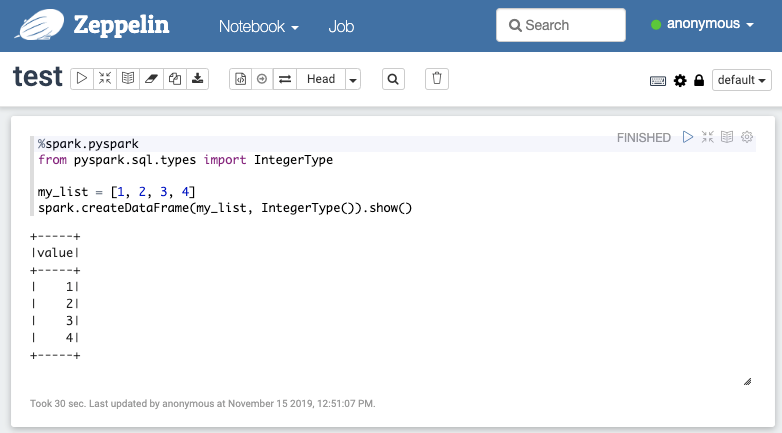
Access spark UI http://localhost:7080/