This repository includes a Knowledge Graph construction project from Turkish Wikipedia pages. This project constructs a Knowledge Graph from Turkish wikipedia dump, using both the unstructured texts and information boxes. It is developed under inzva AI Projects #6 event, with a group of 4 researchers.

We mainly used two repositories. We constructed a pipeline using both of them in order to construct a knowledge graph. First repository , Radboud Entity Linker which is a modular Entity Linker. Second repository is Link which is non-official implementation of the Language Models are Open Knowledge Graphs paper.
For dependency parsing, we used DiaParser . It didn't have pre-trained parser on Turkish, so we trained new parser using UD_Turkish-BOUN dataset. The training dataset contains 7803 sentences for training 979 sentences for development 979 sentences for testing.
| Model | UAS on Dev | LAS on Dev | UAS on Test | LAS on Test |
|---|---|---|---|---|
| bert-base-turkish-cased | 83.20% | 74.83% | 83.05% | 75.41% |
| electra-base-turkish-discriminator | 84.22% | 75.64% | 83.53% | 75.87% |
| convbert-base-turkish-cased | 83.12% | 74.86% | 82.55% | 75.21% |
You can access our dependency parser model from Diaparser library
This script takes as an input a Wikipedia dump and spits out files such as
wiki_redirects.txt,
wiki_name_id_map.txt,
wiki_disambiguation.txt.
You can find WikiExtractor script from here.
from wikipedia2vec import Wikipedia2Vec
wiki2vec = Wikipedia2Vec.load('wikipedia2vec_trained')
wiki2vec.most_similar(wiki2vec.get_entity('Atatürk'), 5)
>>> [(<Entity Mustafa Kemal Atatürk>, 0.9999999), (<Word atatürk>, 0.9274426), (<Word kemal>, 0.782923), (<Entity Kategori:Mustafa Kemal Atatürk>, 0.77045125), (<Entity Yardım:Açıklamalı sayfa>, 0.7423448)]
wiki2vec.most_similar(wiki2vec.get_entity('Fatih Terim'), 5)
>>> [(<Entity Fatih Terim>, 1.0), (<Entity Şenol Güneş>, 0.7102364), (<Entity Müfit Erkasap>, 0.6819058), (<Entity Abdullah Avcı>, 0.67471796), (<Word hiddink>, 0.6672677)]
We used Wikipedia2Vec to obtain page embeddings.
Total number of word occurrences: 457850145
Hyperparameters: window=5, iteration=10, negative=15
You can access Wikipedia2Vec official page from here.
You can access 2021 Turkish Wikipedia Dump from here.
Binary file soon!
We trained a model for Part of Speech Tagging which is trained with Bert Turk language model
Batch size : 8
Epoch : 10
Maximum sequence length : 128
We used UD Turkish IMST Dataset in order to train, test and validate our model.
The results are shown below
| Precision | Recall | F1 | loss |
|---|---|---|---|
| 95.94 | 96.04 | 95.99 | 0.1625 |
You can access our Bert Part of Speech tagging model from here
We trained a Named Entity Recognition which is trained with Convberturk language model
Batch size : 32
Epoch : 5
Maximum sequence length : 512
We used Xtreme Dataset in order to train, test and validate our model. We trained convbert model with merging train and extra files and we got the results on validation file.
The results are shown below
| Precision | Recall | F1 | loss |
|---|---|---|---|
| 95.83 | 96.84 | 96.33 | 0.0665 |
You can access our convbert Named Entity Recognition model from here
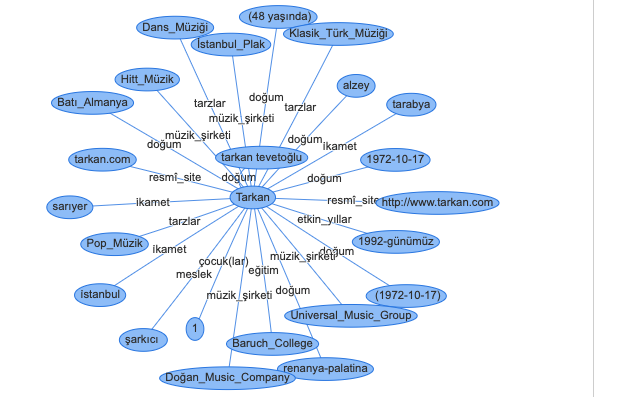
This information box relations extract from Tarkan wikipedia page
We used the combination of Zeyrek and Turkish lemmatizer to apply Lemmatization on words.
We used Turkish WordNet and trnlp gihub repository to collect adjective, adverb and verbs. You can access Turkish WordNet from here You can access trnlp repository from here
| Adjective Count | Adverb Count | Verb Count |
|---|---|---|
| 10092 | 2325 | 13274 |
| Adjective Count | Adverb Count | Verb Count |
|---|---|---|
| 8456 | 1416 | 9788 |
| Adjective Count | Adverb Count | Verb Count |
|---|---|---|
| 18548 | 3741 | 23062 |