Messaging instrumentation abstraction
Especially noticed in the Brave project, there are similar sampling and data policy concerns that apply to messaging in the same was as they do http. Users do not want to individually configure N libraries with similar features, rather one object that each of the relevant libraries can use. This can reduce copy/paste and modeling errors as well. Notably, messaging tracing is complex due to aspects such as producer/consumer relationships. An abstraction can help centralize tooling and documentation in the same way that we do for http Perhaps more importantly, this allows for compatibility tests to occur, also like http-tests, letting instrumentation authors find bugs faster and easier.
| language | status | tools supported |
|---|---|---|
| java | draft | kafka, jms |
The tag names used in spans or metrics will vary, but the data needed will vary less. For example, even if we use a standard name in zipkin for a message channel (topic or queue), such as "messaging.channel", when exporting to other systems such as Amazon, this tag will be renamed. For this reason, we should consider the same parsing style as used in http, which focuses on getting the data independently from how it is named.
When Producer side sends data to a messaging broker:
public Span startSend(Chan channel, Msg message) {
C carrier = adapter.carrier(message);
TraceContext maybeParent = tracing.currentTraceContext().get();
Span span;
if (maybeParent == null) {
span = tracing.tracer().nextSpan(extractor.extract(carrier));
} else {
span = tracing.tracer().newChild(maybeParent);
}
if (!span.isNoop()) {
span.kind(Span.Kind.PRODUCER);
parser.start("send", adapter, channel, message, span.context(), span.customizer());
String remoteServiceName = adapter.brokerName(channel);
if (remoteServiceName != null) span.remoteServiceName(remoteServiceName);
span.start();
}
injector.inject(span.context(), carrier);
return span;
}The following are functions that parse data, noted for whether they are default data, must be supported, or should be supported.
| function | required | default? | description | supported implementations (required implies all must support) |
|---|---|---|---|---|
| channel_name | true | span.tags.messaging.channel_name | kafka, jms | |
| channel_kind | true | span.tags.messaging.channel_kind | kafka, jms | |
| message_id | false | span.tags.messaging.message_id | Message identifier. We choose to name it message_id as most implementations (JMS, AMQP, RocketMQ) |
kafka, jms |
| broker_name | true | span.remote_service_name | kafka, jms | |
| protocol | true | span.tags.messaging.protocol | Messaging protocol and version e.g. kafka, jms, stomp, amqp |
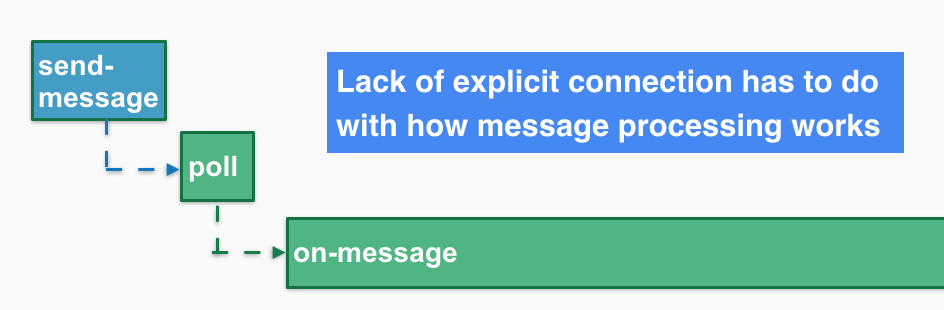
There can be a lag between message consumption and processing. This implies a possible requirement to store the parent span context in the message even for local processing. Another option is an identity-based lookup table.
Here's the code that shows this problem
MessageDispatch md = unconsumedMessages.dequeueNoWait();
// there’s often no stack relationship between message
// consumption and processing!
if (md != null) {
dispatch(md);
return true;
}Here's the concern put visually.
In the case of message brokers, like RabbitMQ or Kafka, a server-side trace could evidence broker-specific actions that could be useful to represent: in the case of RabbitMQ, server-side could be traced to evidence the execution of routing rules.
In kafka, for client-side there are interceptors that Brave is using, but for broker-side, it needs something similar to map its behavior. The idea of a "broker interceptor" has been discussed in the Kafka community and the is a proposal been discussed as well, but haven't been implemented as part of the project yet--though other sites have been experimenting with this (eg. LinkedIn's fork has the conecept of "observer" https://github.com/linkedin/kafka/commit/a378c8980af16e3c6d3f6550868ac0fd5a58682e).
Without this abstraction it's curenntly difficult to hook into how the kafka cluster works.
In general, it's still an open question how to represent spans from the broker side as these are not consumer spans per se.