
We live in an era where Black and White Photos are just the products of digital effects in the modern photography. Yet there are a lot of continuous effort from the historians, vintage art lovers, artists, film producers, or just some random nostalgic person, to try to recover/restore the colours on the old photos/films.
Yeah, this was one of my hobby projects I wanted to try out during the COVID-19 pandemic. So... yeah.
Image editing softwares are commonly used for the image restoration task. However, it requires skills and time to complete the task. It can take minutes to colourise one photo for a photo editing expert.
Instead, autoencoders, as a common neural network architecture usually used to encode/decode image information, might be suitable to automate this task.
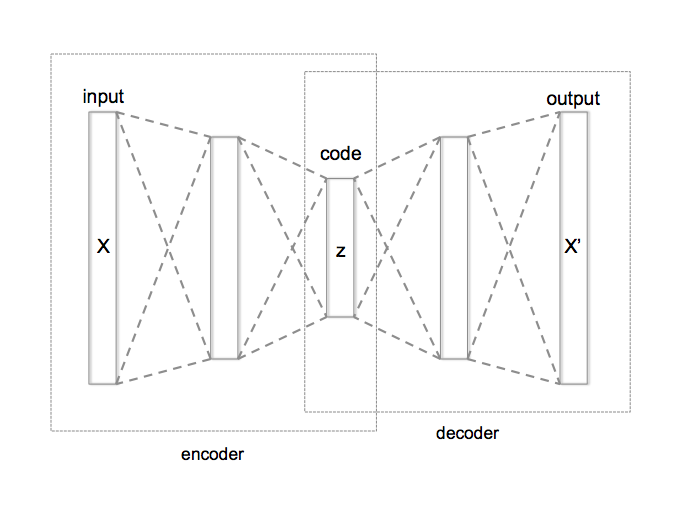
Figure By Chervinskii - Own work, CC BY-SA 4.0, https://commons.wikimedia.org/w/index.php?curid=45555552
The usual usage of the autoencoders is to perform dimensionality reduction on the vector data for lighter transmission or storage.
An image is first sent in as input to the encoder network to get a much smaller and lighter latent space as the representation of the original image. Then, the retrieval/restoration of the image is through a decoder network (usually the inverted form of the encoder), where the latent space representation is passed through as the input, and finally retrieving the original image as the output with minimal loss.
Note that our purpose is to send in a black and white image (or grayscale image) as input and take the colourised image as the output. Thus, we just need to do some modifications on the datasets to achieve that besides building the autoencoders network.
Since this is just a small-scale hobby project, I have narrowed down the scale of the project to just faces. The faces dataset used are available publicly from the Large-scale CelebFaces Attributes (CelebA) Dataset.

The dataset contains 202,599 images of faces.
I have included two Google Colab Notebooks with the implementations of the face colourisation autoencoders in PyTorch and Tensorflow-Keras respectively. All implementation and training details are available inside the Notebook.
To summarize the implementation, besides constructing the autoencoders network with just a simple VGG16 architecture, the training images (black and white photos) are produced by converting all the images to grayscale images (X), while the original coloured images act as the ground truth label (y). All images are represented in RGB channels.

After an hour or more of training, the network merely reconstructed the basic shapes, contours and colours of the person from the grayscale image, the output was blurry and losing all the sharp edges.

Well indeed I was too lazy to wait for another few epochs of training for the network to reproduce sharp edges. Why don't we just treat the current outputs of the autoencoders as the colour masks for the original grayscale images?
The outputs can be masked or blent with the original grayscale images. By doing this we can preserve the sharp edges in the mean time restore the colours.

Some image enhancement techniques can also be done later on the outputs, such as the image sharpening filters and HSV management.

Some other outputs tested:




And this is how the network performed on real black and white photos:





- https://www.flickr.com/photos/29185076@N05/4591829922/
- https://commons.wikimedia.org/wiki/File:Jfk2.jpg
- https://commons.wikimedia.org/wiki/File:Hermann_Rorschach_c.1910.JPG
- https://commons.wikimedia.org/wiki/File:Frida_Kahlo,_by_Guillermo_Kahlo_2.jpg
- https://digital-photography-school.com/7-tips-for-black-and-white-portrait-photography/
{kind=link}
{kind=link}
{kind=link}