Design
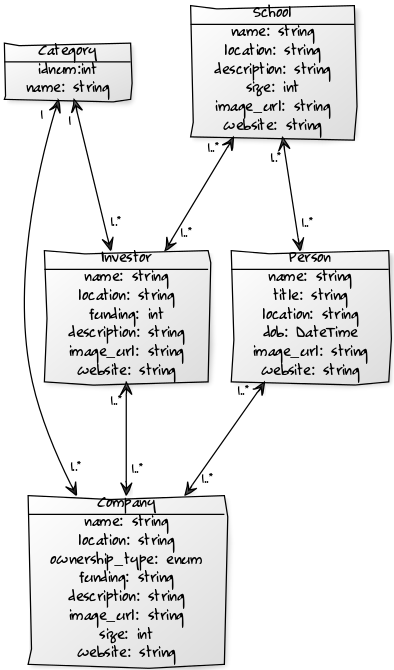
Above is our UML diagram created using this text on yUML:
[Person|name: string; title: string; location: string; dob: DateTime; image_url: string; website: string;]
[Company|name: string; location: string; ownership_type: enum; funding: string; description: string; image_url: string; size: int; website: string;]
[Person]++<1..*-1..*>[Company]
[School|name: string; location: string; description: string; size: int; image_url: string; website: string;]
[School]++<1..*-1..*>[Person]
[School]++<1..*-1..*>[Investor]
[Investor|name: string; location: string; funding: int; description: string; image_url: string; website: string;]
[Investor]++<1..*-1..*>[Company]
[Category|idnum:int; name: string;]
[Category]++<1-1..*>[Investor]
[Category]++<1-1..*>[Company]
We have four models: Company, Person, Investor, and School. Each model connects to two other models. Each company has a CEO, employees, and investors, people work for companies and have attended schools, investors invest in companies and schools, and schools have investors and alumni. Apart from this, each model also has additional information about each instance, such as location, description, website, etc. When creating the models, we set one-to-many and many-to-many relationships by creating tables in our models.py file.
SWEatshop has a simple API to retrieve centralized data regarding companies along with the people, investors and schools of everyone involved. We created a RESTful API in order to satisfy get requests by returning rows from our tables in our Amazon Web Services Relational PostgreSQL Database using Flask-SQLAlchemy. In future versions, we expect to make the API accept POST and UPDATE calls as well so that the AWS database can be updated through API calls. We get most of our model data from the Crunchbase API. The API has information on the companies, people, investments, and a much more. IP API allows us to fill in location information for some of the blank fields in our database by providing a location from the model's website url. We utilize Google Maps API to provide a map to the location of each instance in the instance pages. Clearbit API lets us scrape company websites for logos. Finally, Bing Images API was used to find photos for our person models.
Phase 1: We use JQuery, Javascript, Isotope, Jinja2, Flask, HTML, and Bootstrap to implement sorting and filtering. First we create a template using HTML and Bootstrap. Each item is represented using a Bootstrap card and the data for each card is dynamically populated by Flask and Jinja2. Flask accesses the AWS Relational Database through Flask PostgreSQL SQLAlchemy and renders the retrieved information in the template by means of Jinja2. We then set classes and certain other attributes in the HTML through Flask and Jinja2 so that the filters will know what to do. The filtering and sorting functionality are implemented in the front end through the use of Isotope, JQuery, and embedded Javascript. This allows us to, upon detecting a button click, change the content of the Isotope grid in the HTML template body. In order for Isotope to recognize that an item falls under a particular filter, a class attribute must be set with the name of the filter, and the same name must be set to the respective button’s list of attributes. For the sorting function to know what data to sort by, an attribute must be created in the div surrounding the Bootstrap card for each item. This means that implementation is very simple. All of the instances are rendered on load and sorting/filtering is just a matter of moving the cards around. The Isotope library does this well and simply by importing the library, all the functionality that we need is implemented beautifully.
Reflection on Phase 1 and Planning for Phase 2: There are many downsides to the front-end sorting and filtering approach, though. Initially loading the page can take a very long time. This is because the page needs to find the data from our Amazon Web Services database and then render the images for all of the cards. This is a lot of data to load and therefore. Front-end sorting and filtering was easy and fast for Phase 1 because we only had three instances to query, but it became an unacceptable approach once we started adding 1000+ rows to our database tables. This, of course, is just issues with loading time. There are even more problems with front-end filtering and sorting once Phase 2 functionality is added. Notably, Isotope only can filter and sort the cards within the page. In order to speed up loading times and clean up the models pages, we had to implement pagination. Isotope will not work with pagination because isotope will only be able to filter and sort the items within that particular page. All of this means that once Phase 2 starts, filtering and sorting will have to move to the backend.
Phase 2: The first step was to implement pagination. We started off by trying front-end solutions for ease of implementation and for compatibility with Isotope but the methods that we did find did not work properly for our use case. So, we moved pagination to the back-end. Using Flask-Paginate, we limited the number of elements passed into the HTML template and put in the pagination buttons. Upon click of a page number, we calculate the offset and elements to load and query the database with these parameters. Passing just these to the template means that now, we only need to the render the data and images for a small number of elements. This means that page load is significantly faster. However, it also means that we now need to move the filtering and sorting. Upon button click, we now add the filters and sort details to the URL query and set the window href. The Flask backend extracts these values, queries the database with the approrpriate filters and returns the new set of rows. The template page reloads with the new data. This process is largely simple but one major issue we ran into is saving the button states. Previously, this was not an issue since there was a default on page load and it would change upon button click but now, we need to set the button state. We finally accomplished this task by using jQuery and finding the appropriate values from the href used to access the page.
We obtained most of our data by scraping the Crunchbase RESTful API. Unfortunately we ran into a couple of issues. First, the Crunchbase API would only give us access to a couple hundred instances for free. As we are college students, we can not afford the extra price for the entire API. However, Crunchbase does provide a snapshot of the a hundreds of thousands of models for Companies, Investors, People,and Schools. We combined the data obtained from RESTful API and the snapshot to create a more complete database.
The dump provided by Crunchbase did not consider schools objects and therefore, did not have a lot of information about schools. We could only get the names of the schools that people went to. As a first step, we created a school row and added a relation for every person, checking whether the school name has already been added to the database. Next, we used the IPEDS (Integrated Postsecondary Education Data System) API provided by data.gov to get additional information about the schools. This, since it is provided by the U.S. government, only has a list of U.S. schools. Still, it was a step towards where we needed to be and so, we used this API to fill in more information. We then thought that we could do a lot more if only we had the website URLs of all of these schools. So, next, we wrote a script to look up all of these school names and find possible links for them. We cleaned up this data and then used these URLs to find locations for these schools. Since most schools host their websites on campus servers, we used IP-API to find the IP addresses and from there, the locations of all of these schools. We also went through the meta tags of these school websites to find descriptions but not all schools listed descriptions in their meta tags. In this manner, we filled the schools table with as much information as possible. There are faults with this, though. Especially with the increased use of services such as Cloudflare and AWS, many schools, especially small schools, are hosting their websites elsewhere. Finding investors for these schools was just as hard but by looking specifically for investors that fund schools, we added relationships between investors and schools. Furthermore, since the schools were just added using names, there are many issues with duplicate rows. Notably, certain person rows had a type or ann extra symbol in the name of their school. When adding to our database, this would create multiple rows for the same school. This is certainly a problem but it is difficult to clean up without manually going through all of the rows in the database.
The Crunchbase data was far from complete. Many rows still did not have an image URL and/or a website. We got the websites again using the same technique used for schools and then we had to utilize the ClearBit API in order to obtain the logos for the schools. Clearbit takes in a URL, goes through the website, and finds a logo if there is one. It works most of the time and the API is extremely simple to use without any rate limits. Finally, some companies, investors, and people did not have a location. So, again, we utilized the IP Geolocation API to get location information from the website URL that the models provided in order to create a more complete database. With a lot of these scrapers, there is no guarantee that we get the right information. Our data is far from perfect but it was what we could do with the data that is freely available in the time that we had.
Create a New Person (HTTP POST request)
You can create a new person by utilizing this action. You can provide a JSON object with the first name, last name, title, city name or region name, profile image url, and homepage url.
Create a New Organization (HTTP POST request)
You can create a new company, school, or investor by adding a new organization. In order to create a new company you can provide a JSON object with the name, city name or region name, a short description, a profile image url, and a homepage url. The primary role must be that of a company. In order to create a new school you can provide a JSON object with the name, city name or region name, short description, profile image url, and homepage url. The primary role must be of a school. Finally in order to create a new investor you can provide a JSON object with the name, city name or region name, a short description, a profile image url, and a homepage url. The primary role must be of an investor..
After the first phase, our website had a purple background, default text, and a messy about page. We decided to do a complete redesign of our website and make it look more professional and polished. To begin with, the color scheme changed from purple to black, gray, and white. A new, bolder logo was created for our organization. We also decluttered our about page by moving all of our statistics and important links to the top so that they wouldn’t get lost. The bios were shortened and the tools were organized in a much more efficient manner.
We were tasked with visualizing some of the data from the Food Close to Me group by utilizing their RESTful API. In order to do this, we used the D3.js library. Originally we chose to visualize how many restaurants there are for each type of food. We decided to show this by utilizing a bubble chart that was interactive and moved around when you clicked on a specific catgory. However, we discovered that we could only show 10 categories, otherwise it will take a very long time to load the page. The moving of the bubbles has an exponential time complexity not allowing us to show all the categories. So we are only showing the most popular types of foods. We chose to add another visualization in order to show more data from Food Close to Me. We show what the average rating of each zipcode is by portraying it in a barchat that you can sort by ratings (Higher rating - Lower rating) or by zipcodes.