2 ‐ Instalação e Configuração do Elastic Observability
O Elasticsearch é um motor de busca e análise distribuído, baseado em Lucene, projetado para lidar com uma grande variedade de tipos de dados e formatos. É um componente central do Elastic Stack, atuando como a espinha dorsal para armazenamento, pesquisa e análise de dados.
Funcionalidade Chave:
- Pesquisa e Análise de Dados: O Elasticsearch permite realizar buscas complexas e oferece recursos analíticos poderosos em tempo real, essenciais para interpretar grandes volumes de dados.
- Distribuído por Natureza: Projetado para operar em um ambiente distribuído, oferece alta disponibilidade e capacidade de escalonar horizontalmente, ajustando-se à crescente quantidade de dados e tráfego.
- Schema-Free: Utiliza um formato JSON para os dados, permitindo flexibilidade na indexação de diferentes tipos de dados sem a necessidade de um esquema pré-definido.
No contexto da Elastic Observability, o Elasticsearch desempenha um papel vital no armazenamento e análise de dados de observabilidade (logs, métricas e traces). A capacidade de indexar e pesquisar rapidamente grandes volumes de dados é fundamental para uma observabilidade eficaz, permitindo que as equipes detectem e diagnostiquem problemas de forma rápida e precisa.
A arquitetura do Elasticsearch é projetada para ser altamente escalável e resiliente. Vamos explorar os principais componentes que compõem um cluster do Elasticsearch, incluindo shards, réplicas e tipos de nodes.
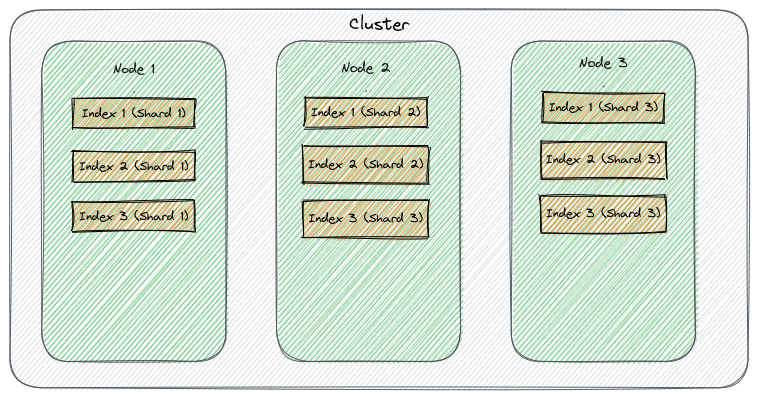
- Definição: Um cluster é uma coleção de um ou mais nodes (servidores) que juntos armazenam seus dados e fornecem recursos de indexação e pesquisa.
- Cluster ID: Cada cluster é identificado por um nome único, que é importante para a comunicação entre os nodes.
- Definição: Um node é um único servidor que faz parte do cluster e participa do armazenamento de dados, pesquisa, e outras operações essenciais.
-
Tipos de Nodes:
- Master Node: Responsável pela gestão do cluster, como a criação ou deleção de índices e a adição ou remoção de nodes.
- Data Node: Armazena dados e executa operações relacionadas a dados, como pesquisas e agregações.
- Ingest Node: Utilizado para pré-processamento de dados antes de serem indexados.
- Coordination Node: Encaminha operações para os nodes apropriados.
- Definição: Um índice é uma coleção de documentos que têm características semelhantes. É identificado por um nome único.
- Funcionalidade: O índice é a unidade de armazenamento e pesquisa no Elasticsearch.
-
Shard:
- Definição: Um shard é uma subdivisão de um índice. Cada índice pode ser dividido em múltiplos shards.
- Propósito: Isso permite a distribuição de dados e a realização de operações de forma paralela em diferentes nodes, melhorando o desempenho e a escalabilidade.
-
Réplica:
- Definição: Cada shard pode ter zero ou mais cópias chamadas réplicas.
- Propósito: Réplicas fornecem redundância de dados, o que aumenta a resiliência do sistema e permite consultas paralelas, melhorando a capacidade de leitura.
- Distribuição Automática de Shards: O Elasticsearch distribui automaticamente shards e réplicas pelos nodes do cluster, balanceando a carga e otimizando o uso de recursos.
- Recuperação de Falhas: Em caso de falha de um node, as réplicas nos outros nodes garantem que não haja perda de dados e que o sistema continue operando normalmente.
- Escalabilidade Horizontal: Adicionar mais nodes ao cluster permite que o Elasticsearch redistribua automaticamente shards e réplicas, aumentando a capacidade e o desempenho.
- Pesquisa Distribuída: As consultas são executadas em paralelo nos shards relevantes, resultando em respostas rápidas, mesmo com grandes volumes de dados.
| Banco de Dados Relacional | Elasticsearch |
|---|---|
| Banco de Dados | Índice |
| Tabela | Tipo |
| Linha | Documento |
| Coluna | Campo |
Explicações sobre a tabela:
-
Banco de Dados vs Índice: No Elasticsearch, um índice é como um 'banco de dados' em um sistema de banco de dados relacional. Os índices permitem que você divida seus documentos em grupos distintos.
-
Tabela vs Tipo: Anteriormente, no Elasticsearch, um 'tipo' era como uma 'tabela' em um banco de dados relacional. No entanto, a partir do Elasticsearch 6.0, os tipos estão em processo de desativação e todos os novos índices poderão conter apenas um tipo.
-
Linha vs Documento: No Elasticsearch, um 'documento' é como uma 'linha' em uma tabela de banco de dados relacional. Cada documento possui um conjunto único de campos e cada campo representa um dado específico naquele documento.
-
Coluna vs Campo: No Elasticsearch, um 'campo' é como uma 'coluna' em uma tabela de banco de dados relacional. Cada campo representa um tipo específico de dado, como texto, data, número etc., que é usado para indexar os documentos de maneira eficiente.
Premissa:
Este guia demonstra a instalação e configuração básica do Elasticsearch em modo "single-node" para o Elastic Observability. A configuração de um cluster Elasticsearch não será abordada neste momento.
Sistema Operacional:
- Linux (Ubuntu 20.04 LTS utilizado como exemplo)
Requisitos:
- Java 11 ou superior instalado
- Espaço livre em disco de acordo com o tamanho da heap size e volume de dados a serem armazenados
** Download e Instalação do Elasticsearch:**
cd /tmp
# Baixar o pacote DEB do Elasticsearch
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-8.12.1-amd64.deb
# Instalar o Elasticsearch
sudo dpkg -i elasticsearch-8.12.1-amd64.debApós a instalação o seguinte resultado é exibido:
--------------------------- Security autoconfiguration information ------------------------------
Authentication and authorization are enabled.
TLS for the transport and HTTP layers is enabled and configured.
The generated password for the elastic built-in superuser is : G9nWw7MUdcRpPTUM_so+
If this node should join an existing cluster, you can reconfigure this with
'/usr/share/elasticsearch/bin/elasticsearch-reconfigure-node --enrollment-token <token-here>'
after creating an enrollment token on your existing cluster.
You can complete the following actions at any time:
Reset the password of the elastic built-in superuser with
'/usr/share/elasticsearch/bin/elasticsearch-reset-password -u elastic'.
Generate an enrollment token for Kibana instances with
'/usr/share/elasticsearch/bin/elasticsearch-create-enrollment-token -s kibana'.
Generate an enrollment token for Elasticsearch nodes with
'/usr/share/elasticsearch/bin/elasticsearch-create-enrollment-token -s node'.
-------------------------------------------------------------------------------------------------
### NOT starting on installation, please execute the following statements to configure elasticsearch service to start automatically using systemd
sudo systemctl daemon-reload
sudo systemctl enable elasticsearch.service
### You can start elasticsearch service by executing
sudo systemctl start elasticsearch.serviceObserve as seguintes linhas:
The generated password for the elastic built-in superuser is : G9nWw7MUdcRpPTUM_so+
'/usr/share/elasticsearch/bin/elasticsearch-reset-password -u elastic'.Iremos ajustar a senha do usuário elastic para uma senha mais simples ok? Para isso vamos executar o comando sugerido para a troca de senha e modo interativo:
# Defina a senha para 123456
/usr/share/elasticsearch/bin/elasticsearch-reset-password -u elastic -i
## Habilitar e Iniciar o serviço Elasticsearch
sudo systemctl daemon-reload
sudo systemctl enable elasticsearch.service
sudo systemctl start elasticsearch.service
# Verificar status do serviço
sudo systemctl status elasticsearchConfiguração da Heap Size:
Abra o arquivo de configuração do Elasticsearch:
sudo vi /etc/elasticsearch/jvm.optionsAdicione a seguinte linha na seção jvm.options:
-Xms1g
-Xmx1g
Configuração do Elasticsearch (elasticsearch.yml):
-
Configuração para SSL/TLS no Transporte e HTTP: Abra o arquivo
/etc/elasticsearch/elasticsearch.ymle adicione as seguintes configurações:cluster.name: cluster-observability node.name: node-1 network.host: 0.0.0.0 http.port: 9200 discovery.type: single-node # ATENÇÃO: comente a seguinte linha #cluster.initial_master_nodes: ["srv"]
Reinicie o Elasticsearch:
Após configurar os certificados e editar o elasticsearch.yml, reinicie o serviço do Elasticsearch para aplicar as mudanças.
sudo systemctl restart elasticsearchVerificação: Verifique se o Elasticsearch está configurado corretamente com SSL/TLS executando:
curl -X GET "https://localhost:9200" -u "usuario:senha" -kSubstitua "usuário:senha" pelas credenciais apropriadas.
Claro, vamos reescrever o passo a passo para instalar o Kibana em um sistema Ubuntu, desta vez considerando o download do pacote .deb para instalação. Este método é útil se você precisar de uma versão específica do Kibana ou se preferir fazer a instalação manualmente ao invés de usar o repositório.
Primeiro, você precisa baixar o pacote .deb do Kibana do site oficial do Elasticsearch. Certifique-se de escolher a versão compatível com sua versão do Elasticsearch.
wget https://artifacts.elastic.co/downloads/kibana/kibana-8.12.1-amd64.debApós o download, instale o Kibana usando o pacote .deb baixado.
sudo dpkg -i kibana-8.12.1-amd64.debGere um token de inscrição para conectar o Kibana ao Elasticsearch.
sudo /usr/share/elasticsearch/bin/elasticsearch-create-enrollment-token -s kibanaAnote o token gerado.
sudo /usr/share/kibana/bin/kibana-setup --enrollment-token <token_gerado>Execute o seguinte comando:
sudo /usr/share/kibana/bin/kibana-encryption-keys generate -q >> /etc/kibana/kibana.yml # Gerando certificado auto-assinado:
sudo /usr/share/elasticsearch/bin/elasticsearch-certutil cert --self-signed --pem
# Informe o caminho para salvar os certificados:
Please enter the desired output file [certificate-bundle.zip]: /etc/kibana/certs.zip
#Instale o unzip:
sudo apt install unzip
#Descompacte o certificados em /etc/kibana:
sudo unzip /etc/kibana/certs.zip -d /etc/kibana/Observe que os arquivos estão no diretório: /etc/kibana/instance
server.port: 5601
server.host: "0.0.0.0"
server.ssl.enabled: true
server.ssl.certificate: /etc/kibana/instance/instance.crt
server.ssl.key: /etc/kibana/instance/instance.keySalve e saia do arquivo
Inicie o serviço do Kibana
sudo systemctl start kibanaApós a inicialização, verifique se o Kibana está corretamente conectado ao Elasticsearch.
http://<seu_ip_aqui>:5601
As versões 8 do elasticsearch oferece a configuração de segurança de forma automática, ou seja, basta apenas descompactar o elasticsearch e iniciá-lo que ele irá realizar as seguintes configurações automáticas:
- Certificados e chaves para TLS são gerados para as camadas de transport e HTTP.
- As configurações de TLS são gravadas no arquivo elasticsearch.yml.
- Uma senha é gerada para o usuário elastic.
- Um token é gerado para o Kibana. Vamos então iniciar nossa instância elasticsearch usando esse método:
sudo -i
useradd -d /opt/elastic -m elastic
chown elastic.elastic /opt/elastic -R
echo "elastic - nofile 65536" >> /etc/security/limits.conf
echo "vm.swappiness = 1" >> /etc/sysctl.conf
echo "vm.max_map_count = 262144" >> /etc/sysctl.conf
swapoff -a
sysctl -psu - elastic
cd /opt/elastic
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-8.12.1-linux-x86_64.tar.gz
tar zxfv elasticsearch-8.12.1-linux-x86_64.tar.gz
mv elasticsearch-8.12.1 elastic-instancia1
mkdir elastic-instancia1/config/certssu - elastic
cd /opt/elastic/elastic-instancia1
vi config/elasticsearch.yml
cluster.name: cluster-tornis
node.name: node1cd /opt/elastic/elastic-instancia1
vi config/jvm.options.d/lab.options
-Xms1g
-Xmx1gcd /opt/elastic/elastic-instancia1
./bin/elasticsearchObservação: Fique atendo as mensagens na tela do console pois será exibido os informações de tokens e senha do usuário Elastic
cd /opt/elastic/elastic-instancia1
./bin/elasticsearch-reset-password -i -u elastic
This tool will reset the password of the [elastic] user.
You will be prompted to enter the password.
Please confirm that you would like to continue [y/N]y
informe a senha 123456su - elastic
cd /opt/elastic/
wget https://artifacts.elastic.co/downloads/kibana/kibana-8.12.1-linux-x86_64.tar.gz
tar zxfv kibana-8.12.1-linux-x86_64.tar.gz
mv kibana-8.12.1 kibana
cd kibana vi /opt/kibana/config/kibana.yml
server.host: "0.0.0.0"Vamos gerar um novo token para que a kibana possa conectar no cluster. Para isso, vamos gerar o token na instância 1 conforme comandos abaixo:
su - elastic
cd /opt/elastic/elastic-instancia1
./bin/elasticsearch-create-enrollment-token -s kibanaGuarde o token gerado pois iremos utiliza-lo em breve!
su - elastic
cd /opt/elastic/kibana
./bin/kibanaObservação: No console o Kibana exibirá uma url. Abra seu navegador e acessa a url informada conforme exemplo abaixo:

A seguinte tela é exibida. Informe o token fornecido pelo elasticsearch para o ingresso do kibana conforme exemplo e depois clique no botão "Configure Elastic". Agora o Kibana solicita um token de validação para que a configuração possa iniciar. Esse token está na tela de start do Kibana

Observação: Algumas instalações podem solicitar um novo token pós fornecimento do token. Esse token de 6 caracteres está localizado no console quando vc iniciou o Kibana
Vamos gerar um novo token para que a instância 2 possa ingressar no cluster. Para isso, vamos gerar o token na instância 1 conforme comandos abaixo:
su - elastic
cd /opt/elastic/elastic-instancia1
./bin/elasticsearch-create-enrollment-token -s nodeSalve o Token
cd /opt/elastic
tar zxfv elasticsearch-8.12.1-linux-x86_64.tar.gz
mv elasticsearch-8.12.1 elastic-instancia2Vamos agora ajustar os seguintes parâmetros do arquivo elasticsearch.yml na instância 2. Para isso siga o modelo abaixo:
cd /opt/elastic/elastic-instancia2
vi config/elasticsearch.yml
cluster.name: cluster-tornis
node.name: node2
http.port: 9201
transport.port: 9301Crie o arquivo lab.options e adicione os valores de Xmx e Xms conforme exemplo abaixo:
cd /opt/elastic/elastic-instancia2
vi config/jvm.options.d/lab.options
-Xms1g
-Xmx1gSalve o arquivo e vamos iniciar a nossa instância 2.
cd /opt/elastic/elastic-instancia2
./bin/elasticsearch --enrollment-token <coloque o token aqui>Vamos gerar um novo token para que a instância 3 possa ingressar no cluster. Para isso, vamos gerar o token na instância 1 conforme comandos abaixo:
su - elastic
cd /opt/elastic/elastic-instancia1
./bin/elasticsearch-create-enrollment-token -s nodeSalve o Token
cd /opt/elastic
tar zxfv elasticsearch-8.12.1-linux-x86_64.tar.gz
$ mv elasticsearch-8.12.1 elastic-instancia3Vamos agora ajustar os seguintes parâmetros do arquivo elasticsearch.yml na instância 3. Para isso siga o modelo abaixo:
cd /opt/elastic/elastic-instancia3
vi config/elasticsearch.yml
cluster.name: cluster-tornis
node.name: node3
http.port: 9203
transport.port: 9303Crie o arquivo lab.options e adicione os valores de Xmx e Xms conforme exemplo abaixo:
cd /opt/elastic/elastic-instancia3
vi config/jvm.options.d/lab.options
-Xms1g
-Xmx1gSalve o arquivo e vamos iniciar a nossa instância 3.
cd /opt/elastic/elastic-instancia3
./bin/elasticsearch --enrollment-token <coloque o token aqui>Em qualquer instancia execute o comando abaixo:
curl -X GET 'https://localhost:9200/_cat/nodes?v' -k -u elastic Deverá ser exibido 3 linhas contendo as informações das 3 instancias configuradas