Challenge
We are planning the 5th WBA Hackathon with the theme of working memory. Since working memory is necessary for ‘fluid’ cognitive functions such as planning, its realization is one of the important steps toward AGI.
(Delayed) Match-to-sample (DM2S) tasks will be used. A match-to-sample (MTS) task is a task to find matching figures among distractor figures.
In a delayed MTS task, the original figure is shown, and then hidden, so you have to remember its appearance. Two or more candidates for the matching figure are displayed, and the correct (matching) one must be selected.
The correct figure is selected by pressing a button (human player) or generating an action (computer agent).
A baseline solution will be provided that solves a subset of the challenge in a modular way, enabling participants to further develop the performance, capability, and biological similarity of the solution.
Gameplay in the challenge is organized into Sessions. A session has 3 periods - a Tutoring period, in which the correct logic for the game is demonstrated several times; an inter-period, which signals transition from the Tutoring period, and a Gameplay period, in which the Agent (or human) player must generate the correct actions.
Game rules and logic persist for the duration of one Session only. Each Agent must complete many sessions.

The challenge is organized as 3 phases:
-
Pretraining. During pretraining, Agents are allowed to slowly (statistically) learn typical features in the environment and how to control their gaze and select actions. However, no rewards are provided. Pretraining must therefore be unsupervised, or self-supervised according to some internal goals. The idea of pretraining is to develop some core capabilities before learning about the actual task.
-
Training. During training, Agents are provided with Reward signals that indicate the correct response (or not). During this phase, Agents should learn strategies for solving the different game types, and potentially how to detect the current game logic by observing the tutoring actions.
-
Evaluation. In the Evaluation phase the Agent must not permanently learn. Rewards are provided for consistency and performance measurement. However, the Agent can vary its internal state during Sessions, representing temporary or fast learning in response to observed Tutoring or Rewards.
The objective is for the Agent to learn to use Working Memory to complete tasks. We envisage that the multi-task scenario presented requires working memory to retain current game rules and - in the delayed tasks - original stimulus figure. The pretraining and training phases are intended to permit lifelong learning of basic visual processing and motor strategies, and then learning to adapt these to a specific task.
The agent is assumed to have central and peripheral vision (like human beings). That is, only the central field of vision has high resolution. In order to recognize a figure precisely, the agent has to capture the figure in the central field. Note that comparing figures this way requires working memory.
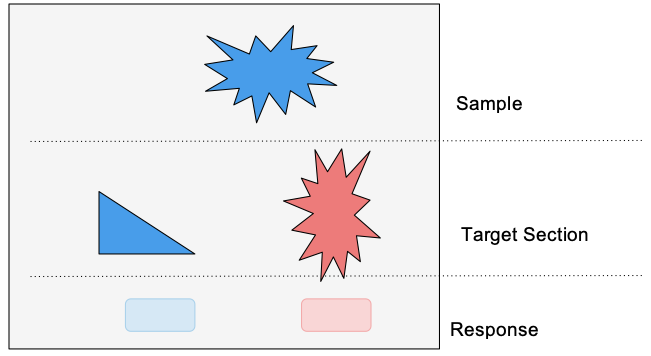
The screen presented to the Agent is divided into 3 areas. At the top is the Sample area, where the original stimulus figure is displayed. The middle row contains the matching figure and one or more distractor figures. The bottom row contains buttons corresponding to the figures. The correct action is to "press" the button below the matching figure (In the example above, the shape of the correct figure is the same as the sample, while the color and orientation may differ. This is because in this session, the task is shape-matching.) Note that an option for "no matching figure" may be added in the hackathon as an additional game type. If the agent responds correctly, it is rewarded (+1). An incorrect answer results in a reward of -1.
In the figure below, the full list of screens displayed are shown with numbers to indicate order. Specifically, the "delayed" task is illustrated, where the original sample is hidden before the choices are displayed. Note that as shown in the Session and Phases diagram above, the Tutoring and Gameplay phases may repeat many times. The delay between each screen may vary, and be up to a couple of seconds. The Agent should function asynchronously with potentially many iterations completed for each screen.

There are two possible approaches to this challenge:
-
Slowly reinforcement-learning the meta-solution to notice game rules during tutoring and then perform the correct actions as appropriate.
-
Few-Shot imitation learning of the correct gameplay (doesn't require rewards).
There are six game types, i.e., delayed or non-delayed (2 types) × 3 types of features to be attended (colors, shapes, and bar positions) (see figure for example bar positions).
Operations such as rotation and expansion may be applied to the figures to be compared (invariant object identification). In the delayed match-to-sample task, the judgment must be done after the reference figure disappears from the screen. Given a new task set, the agent is to learn which features should be attended from a few example answers presented before working on the task (few-shot imitative rule learning, although a slowly reinforcement learning approach is also viable).
Delayed matching to sample task: The agent has to remember the sample to match the target that appears after the sample disappears.
Non-delayed matching to sample task: When the agent matches the sample to the target, the sample is present. While this is easier than delayed tasks, the agent still has to remember the sample figure as it moves its gaze from the sample to the target.
The attribute that determines a correct "match" to the sample figure varies between Sessions. In each Session, one attribute should be used to match the original sample. This attribute can be discovered during Tutoring.
- Colors: The agent is to attend the color of the sample and ignores other features. The figure in the correct target may differ in its shape, size, and orientation from the sample figure. There will be 4 colors: Light Blue, Light Green, Yellow, Pink.
- Shapes: The agent is to attend the shape of the sample and ignores other features. The figure in the correct target may differ in its color, size, and orientation from the sample figure. There will be 5 shapes: Barred_Ring, Triangle, Crescent, Heart, Pentagon.
- Transformations (×3). No transformation, size reduction, orientation change (+/-45°)
- Bar positions: The agent is to attend the position of the bar in the sample and ignores other features. The figure in the correct target may differ in its shape, color, size, and orientation from the sample figure (it is to test the cognition of where the figure is placed). There will be 4 positions (see figure below):

Each task has ten runs to use the average score.
- Non-delayed shape: 60 points total
- Non-delayed color: 20 points total
- Non-delayed bar position: 20 points total
- Delayed shape: 120 points total
- Delayed color: 40 points total
- Delayed bar position: 40 points total
Total score: 300 points total
The agent is will implement to have central and peripheral vision (like human beings). That is, only the central field of vision has high resolution. In order to recognize the figures precisely, the agent has to capture the figure in the central field. Comparing figures this way requires working memory. In addition the Agent must have motor strategies (optionally pre-trained) to explore the full screen and find the figures that are relevant to the task.
The figure below shows a mockup of typical vision sensor data as captured by the Agent.

In the non-delayed sample matching task, even though the sample figure is presented during the selection of a target, WM is still required as the agent has to retain information during gaze shifting to the candidate matches.
Gaze control strategies are an important aspect of the challenge. Studies of human gaze behaviour show that it is highly task dependent (see figure below, from Wikipedia, citing a study by Yarbus (1967)). This implies higher cognitive functions influence gaze behaviour.

{kind=link}