Mirage is a tool that automatically generates fast GPU kernels for PyTorch programs through superoptimization techniques. For example, to get fast GPU kernels for attention, users only need to write a few lines of Python code to describe attention's computation. For a given PyTorch program, Mirage automatically searches the space of potential GPU kernels that are functionally equivalent to the input program and discovers highly-optimized kernel candidates. This approach allows Mirage to find new custom kernels that outperform existing expert-designed ones.
The quickest way to try Mirage is installing the latest stable release from pip:
pip install mirage-projectWe also provide some pre-built binary wheels in the Release Page. For example, to install mirage 0.2.2 compiled with CUDA 12.2 for python 3.10, using the following command:
pip install https://github.com/mirage-project/mirage/releases/download/v0.2.2/mirage_project-0.2.2+cu122-cp310-cp310-linux_x86_64.whlYou can also install Mirage from source code:
git clone --recursive https://www.github.com/mirage-project/mirage
cd mirage
pip install -e . -vMirage can automatically generate fast GPU kernels for arbitrary PyTorch programs. The Mirage-generated kernels can be integrated into a PyTorch program with a few lines of code changes. As an example, we show how to use Mirage to generate kernels that fuse RMSNorm and Linear to accelerate Transformer-based large language model computation. More examples are available in tutorials.
The follow code snippet shows a native PyTorch implementation for a Transformer layer in LLaMA-3-8B.
rms_norm_1 = torch.nn.RMSNorm(4096)
rms_norm_2 = torch.nn.RMSNorm(4096)
Y = rms_norm_1(X)
Z = torch.matmul(Y, Wqkv)
O = attention(Z)
U = rms_norm_2(Z)
V = torch.matmul(U, W13)
V1, V3 = V.chunk(2, -1) # split omitted in the above figure
output = torch.matmul(silu(V1) * V3, W2) # silu and this matmul omitted in the above figure
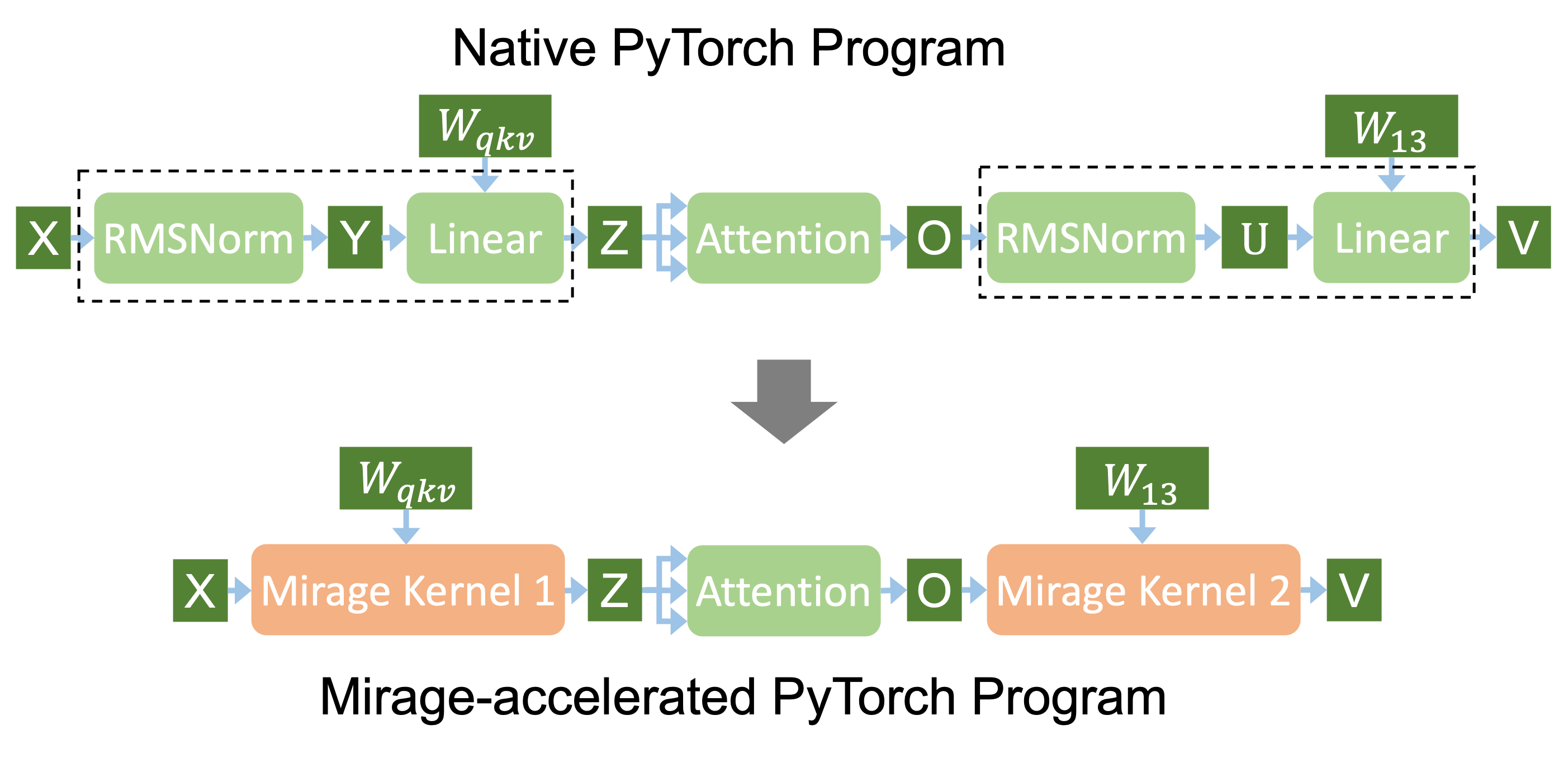
To accelerate Transformer computation, we can use Mirage to generate GPU kernels that fuse RMSNorm and Linear, as shown in the code snippet below. Generating optimized kernels only requires write a few lines of code to describe the desired computation. The get_mirage_kernel function below returns the best kernel discovered by Mirage. These kernels can directly run as functions in your PyTorch programs. This kernel is 1.5–1.7x faster than running the two operators separately in PyTorch.
def get_mirage_kernel(batch_size, output_dim):
graph = mi.new_kernel_graph()
X = graph.new_input(dims=(batch_size, 4096), dtype=mi.float16)
Wqkv = graph.new_input(dims=(4096, output_dim), dtype=mi.float16)
Y = graph.rms_norm(X, normalized_shape=(4096,))
Z = graph.matmul(Y, Wqkv)
graph.mark_output(Y)
return graph.superoptimize()
kernel_1 = get_mirage_kernel(batch_size, output_dim=Wqkv.shape[-1])
kernel_2 = get_mirage_kernel(batch_size, output_dim=W13.shape[-1])
Z = kernel_1(inputs=[X, Wqkv])
O = attention(Z)
V = kernel_2(inputs=[Z, W13])
V1, V3 = V.chunk(2, -1) # split omitted in the above figure
output = torch.matmul(silu(V1) * V3, W2) # silu and this matmul omitted in the above figurePlease let us know if you encounter any bugs or have any suggestions by submitting an issue.
We welcome all contributions to Mirage from bug fixes to new features and extensions.
A paper describing Mirage's techniques is available on arxiv. Please cite Mirage as:
@misc{wu2024mirage,
title={A Multi-Level Superoptimizer for Tensor Programs},
author={Mengdi Wu and Xinhao Cheng and Oded Padon and Zhihao Jia},
eprint={2405.05751},
archivePrefix={arXiv},
year={2024},
}Mirage uses Apache License 2.0.