| Name:Version | Documentation | Purpose | Alternatives | Advantages |
|---|---|---|---|---|
| Terraform 1.5.4 | Docs | Hardware Provisioner Initial Setup |
Salt Ansible |
1. Easy syntax 2. Sufficient community and documentation 3. Much better suited for hardware provisioning |
| Hetzner Provider 1.42.1 | Docs | Deploying servers | Vultr DigitalOcean |
1. Cheaper :) 2. Good community overlooking provider |
| Ansible 2.15.2 | Docs | Automating Tasks | Salt |
1. No footprint on target hosts |
| Ubuntu 22.04 | Docs | Operating system | Debian Centos |
1. Bigger community 2. Faster releases than debian 3. Bigger community than any other OS 4. Not cash grapping like centos (Yet :)) |
| Victoriametrics latest | Docs | Time-series Database | InfluxDB Prometheus |
1. High performance 2. Cost-effective 3. Scalable 4. Handles massive volumes of data 5. Good community and documentation |
| vmalert latest | Docs | Evaluating Alerting Rules | Prometheus Alertmanager |
1. Works well with VictoriaMetrics 2. Supports different datasource types |
| vmagent latest | Docs | Collecting Time-series Data | Prometheus |
1. Works well with VictoriaMetrics 2. Supports different data source types |
| Alertmanager latest | Docs | Handling Alerts | ElastAlert Grafana Alerts |
1. Handles alerts from multiple client applications 2. Deduplicates, groups, and routes alerts 3. Can be plugged to multiple endpoints (Slack, Email, Telegram, Squadcast, ...) |
| Grafana latest | Docs | Monitoring and Observability | Prometheus Datadog New Relic |
1. Create, explore, and share dashboards with ease 2.Huge community and documentation 3. Easy to setup and manage 4. Many out of the box solutions for visualization |
| Elasticsearch latest | Docs | Document based database, Full-text search engine | Loki Mongo |
1. Full indexing capability on the content 2. Great community and documentation 3. Production proven |
| Nodeexporter latest | Docs | Hardware and OS Metrics | cAdvisor Collectd |
1. Measure various machine resources 2. Pluggable metric collectors 3. Basic standard for node monitoing |
| Elasticsearch exporter latest | Docs | Elastic metrics | metricbeat |
1. Much easier to setup than metricbeat 2. Easily adoptable for monitoring stack 3. The project has solid place in prometheus-community |
| Kibana latest | Docs | Data visualization tool | Grafana, Power BI |
1. Perfect integration with Elasticsearch 2. Godd community and documentation 3. Perfect for log analysis whcih is my purpose here (not metric analysis) |
| Docker latest | Docs | Application Deployment and Management | containerd podman |
1. Much more bells and wistels are included out of the box comparing to alternatives 2. Awsome community and documentation 3. Easy to work with |
Note Each ansible role has a general and a specific Readme file. It is encouraged to read them before firing off
p.s: Start with the readme file of main setup playbook
- Create an Api on hetzner
- Create a server as terraform and ansible provisioner (Needless to say that ansible and terraform must be installed)
- Clone the project
- In modular_terraform folder create a terraform.tfvars
- The file must contain the following variables
- hcloud_token "APIKEY"
- image_name = "ubuntu-22.04"
- server_type = "cpx31"
- location = "hel1"
- The file must contain the following variables
- Run terraform init to create the required lock file
- Before firing off, run terraform plan to see if everything is alright
- Run terraform apply
- Go Drink a cup of coffe and come back in 10 minutes or so (Hopefully everything must be up and running by then (: )
- No automation for scaling or maintenance (after the initial set up)
- Terraform is limited to Hetzner
- Grafana datasource must be set manually http://IP_ADDRESS_:8428
- Run the following command for terraform to install dependencies and create the lock file
terraform init
- Run the following command and check if there are any problems with terraform
terraform plan
- Apply terraform modules and get started
terraform apply
- Check if kibana works and elastic indices are created as intended
Note Keep in mind that in this demo, a sample data is being routed to elastic for demonstration purpose
- Check if snapshotting and index life cycle works (SLM and ILM)
Note Keep in mind that in Operation guide section of this project you can see every step for setting up SLM and ILM
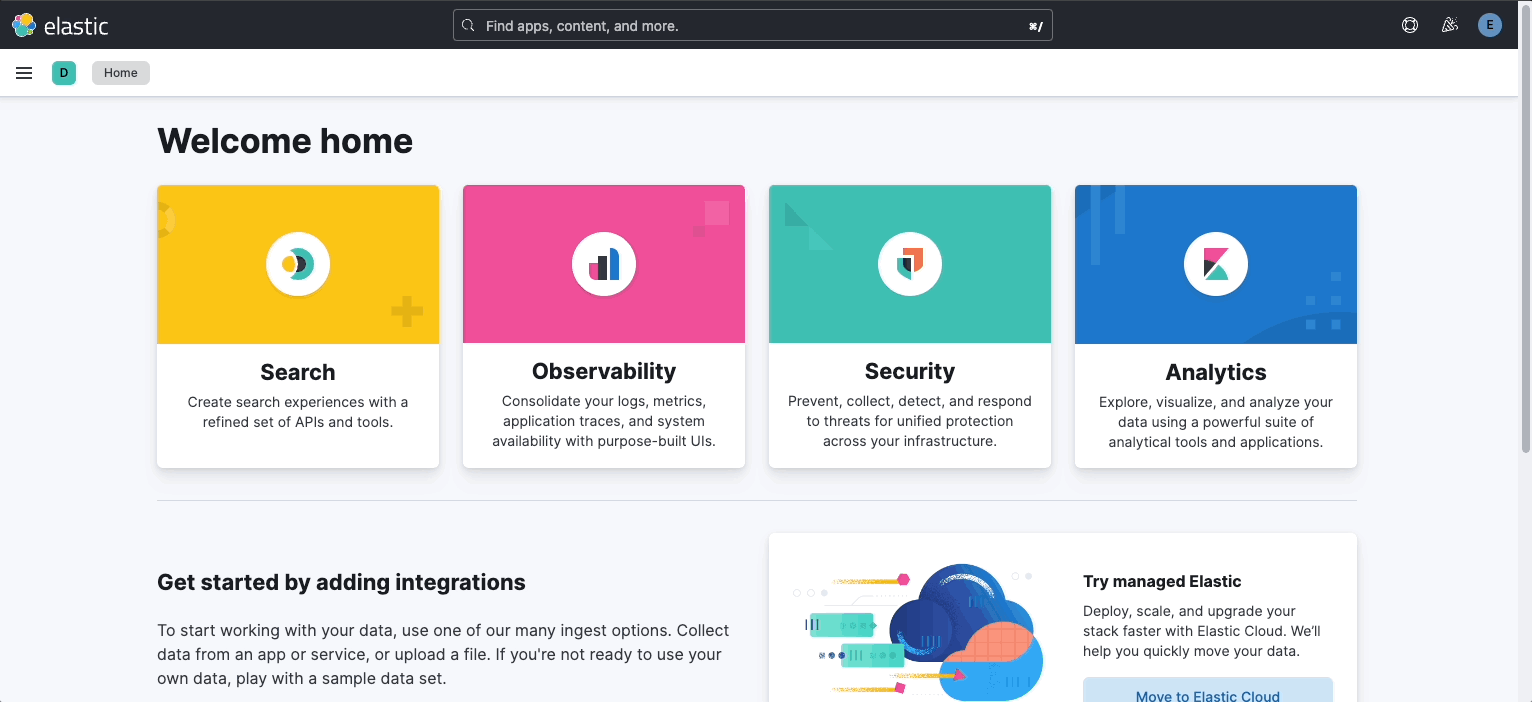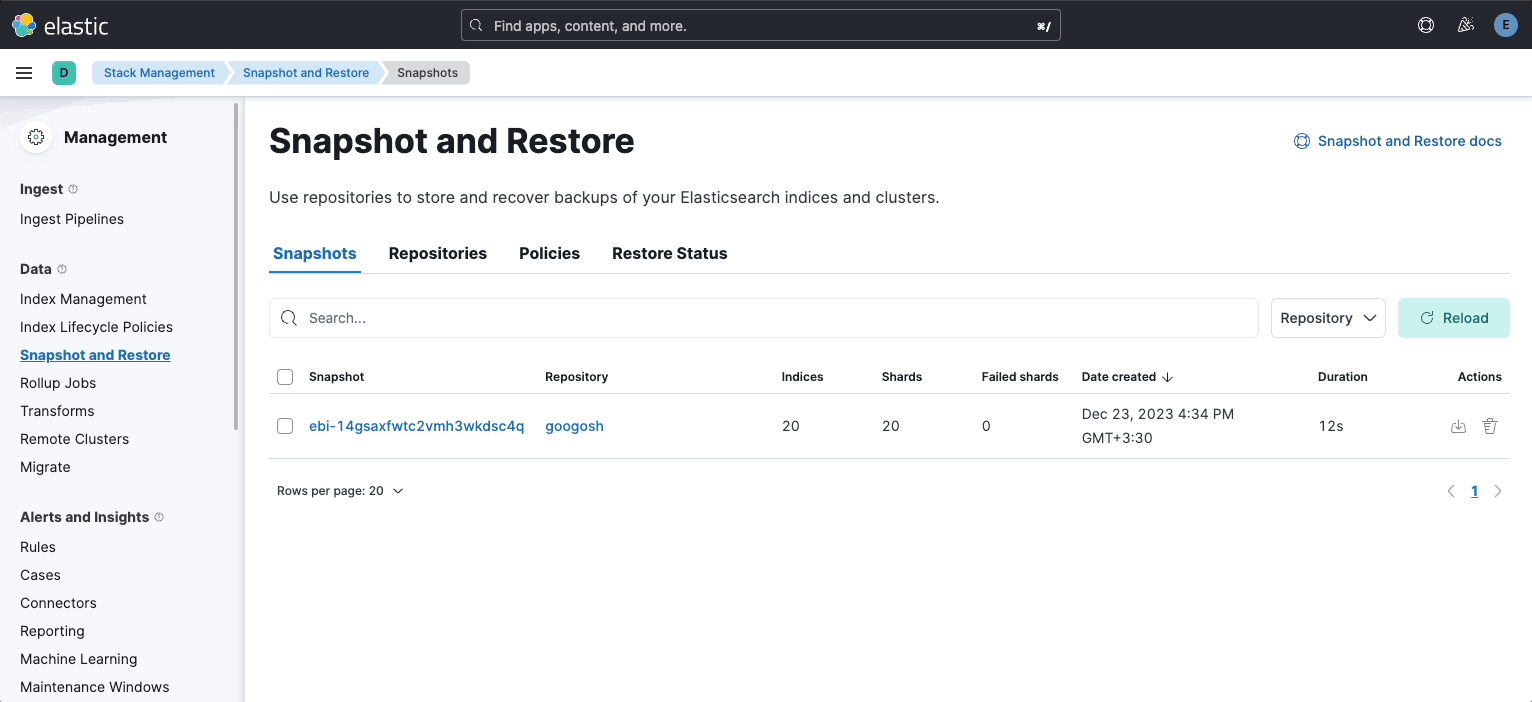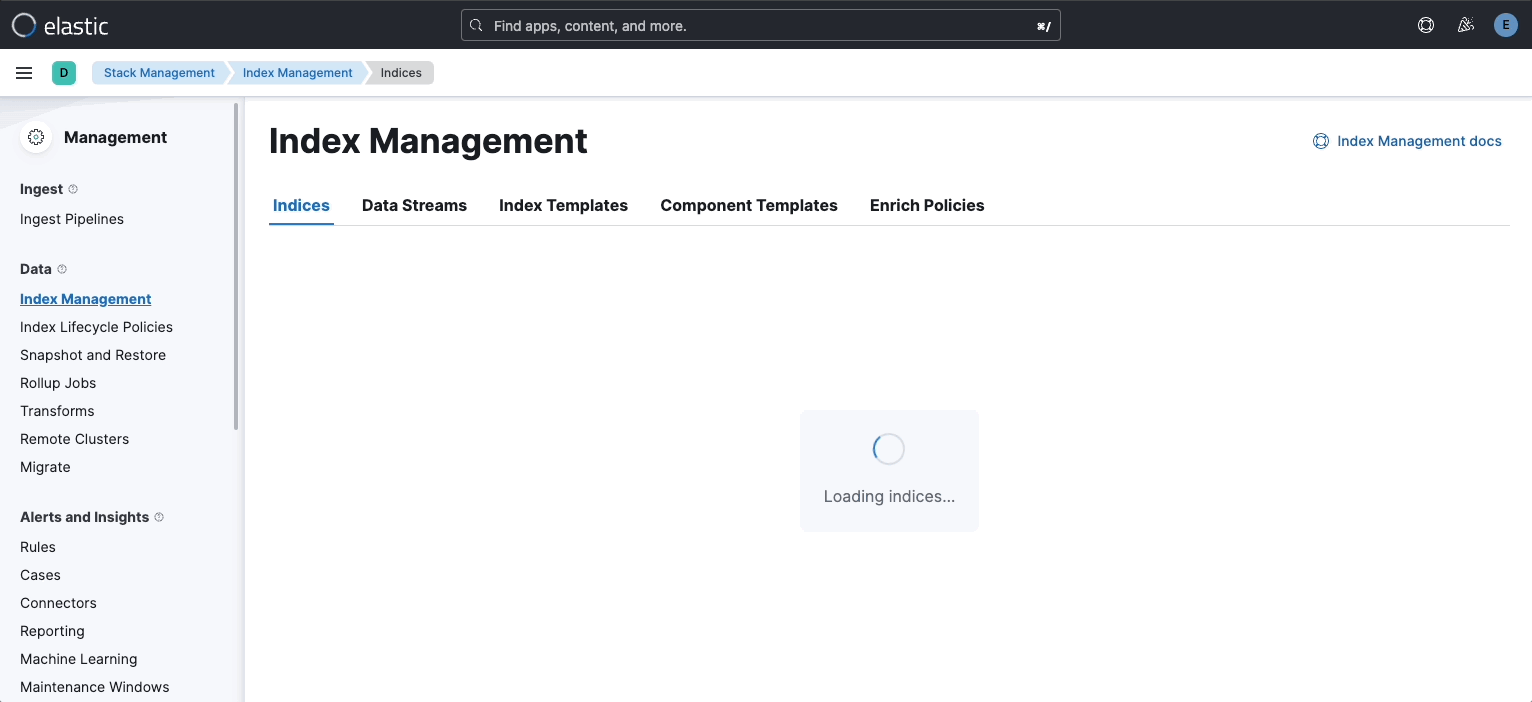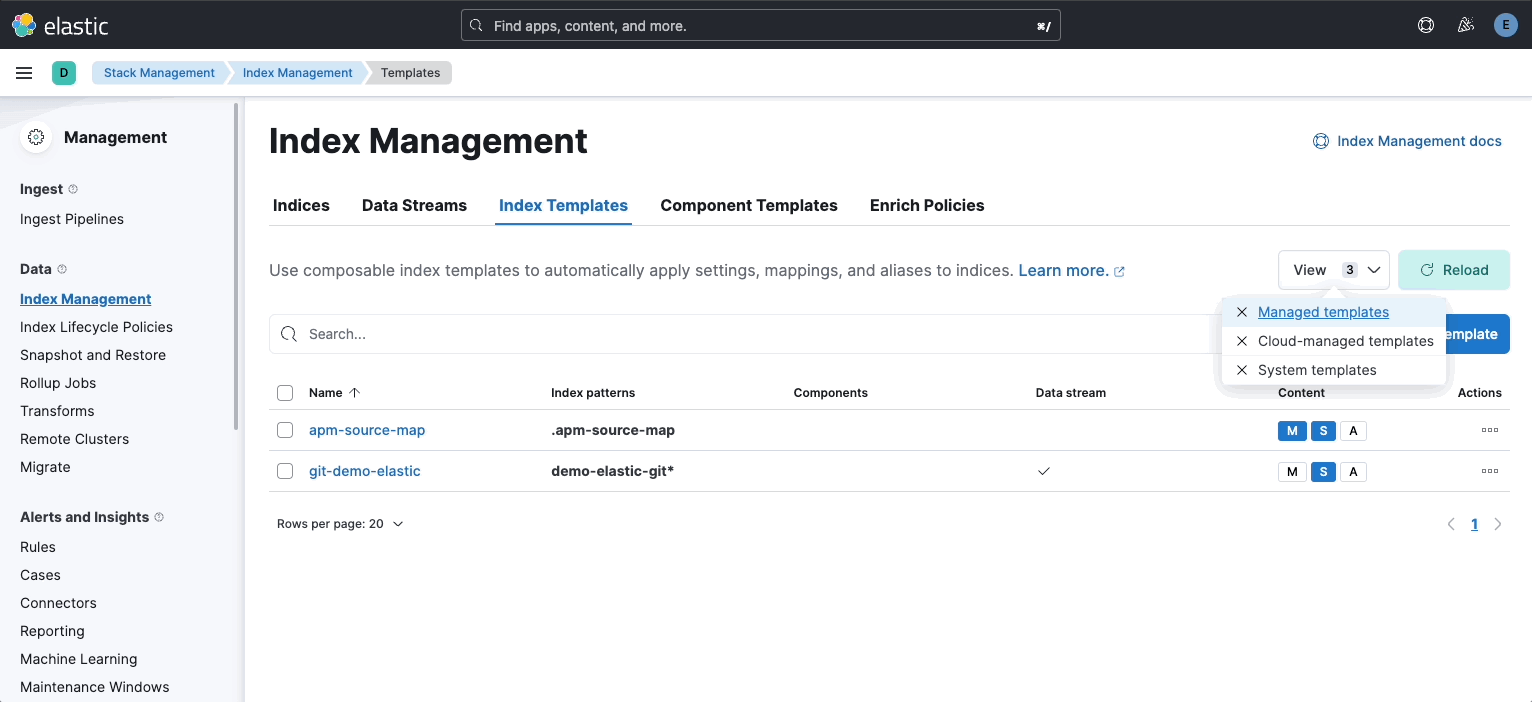
- Check if snapshots are properly stored in the bucket
Note Seeing if the cluster is properly using the s3 bucket which has been set as the repository for snapshots

- Checking the monitoring stack
Note All dashboard are provisioned To add custom dashbaord on load, add it to /Ansible/roles/Victoria_Metrics/files/Grafana/provisioning/dashboards as a .json file. It would automatically be loaded to Grafana Just keep in mind that you have to also copy the dashbaord using ansible to the remote destination
- To Clean up everything (including the nodes themselvs)
terraform destroy