A collection of resources on learning 3D object from 2D images.
Alias: image-based 3D reconstruction / Rendering
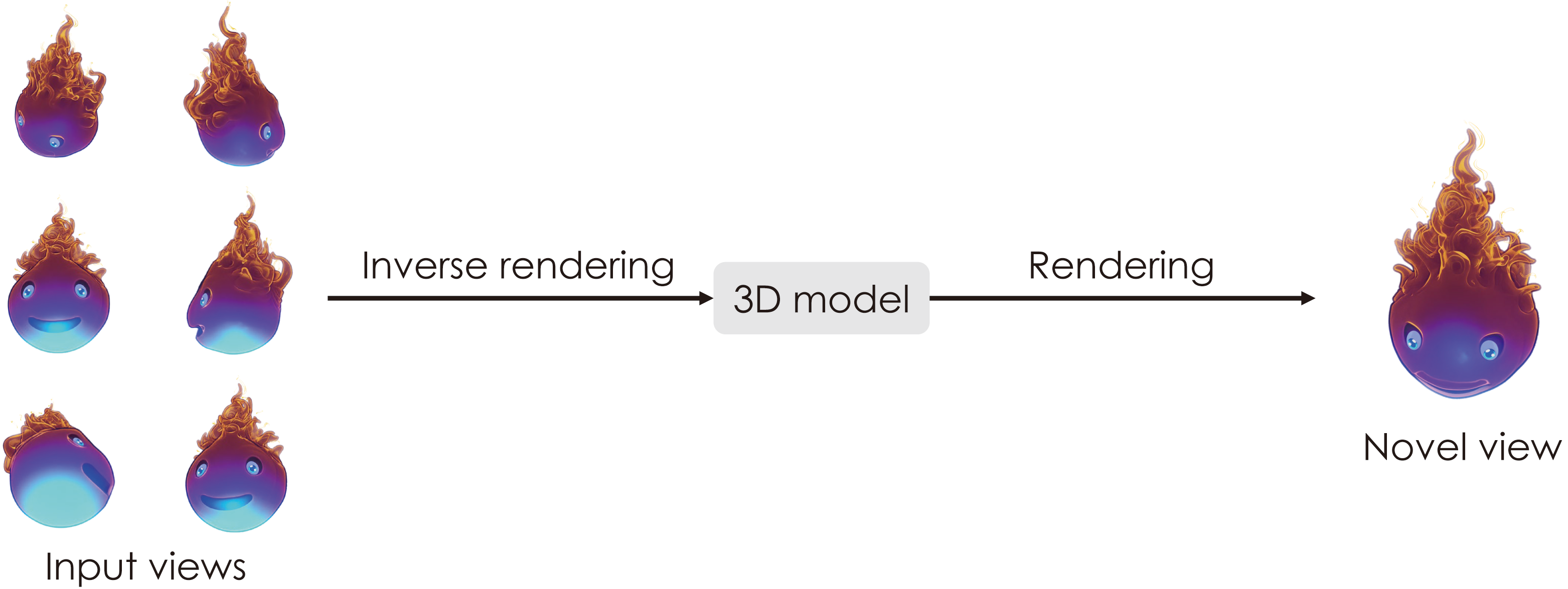 (figure from https://yconquesty.github.io/)
(figure from https://yconquesty.github.io/)
中文介绍
这一任务是从一组多视角的图像中,学习出一个3D模型,然后再渲染得到其他视角的图像。因此我们可以将它拆分为两个部分,前一部分叫逆渲染 (inverse rendering),为什么这样叫呢,是因为渲染过程是从3D模型到2D图像的投影,那么反过来,从图像得到模型,就是逆渲染;后一部分就是渲染。
[Impact & sustained attention] 3D reconstruction from multiple RGB images is a fundamental problem in computer vision with various applications in robotics, graphics, animation, virtual reality, and more. Recently, significant advances have been made towards complete reconstruction (geometry and appearance/texture) from an RGB image input.
[Problem introduction] The reconstruction is often accompanied by representation, and the whole process is under the assumptions of known materials, viewpoints, and lighting conditions. If the materials, viewpoints, and lighting are not known, this will be generally an ill-posed problem because combinations of geometry, materials, viewpoints, and lighting can produce exactly the same photographs (ambiguity). As a result, without further assumptions, no single algorithm can correctly reconstruct the 3D geometry from photographs alone.
[Old MVS] Multi-View Stereo (MVS) methods are a classic branch to solve this tough challenge. It refers to the problem of capturing a scene from a novel viewpoint given a few input images.
[Novel neural methods] Beyond methods of traditional representation (voxel, grid, mesh) and relied on 3D supervision, the recent popular approaches utilizing neural implicit representation (coordinate-based neural networks) yield state-of-the-art performance because they tend to produce smoothness bias of neural networks. The key idea behind is to use compact, memory efficient multi-layer perceptrons (MLPs) to parameterize implicit shape representations such as occupancy or signed distance fields (SDF).
Some works use differentiable surface rendering to reconstruct scenes from multi-view images. Neural radiance fields (NeRFs) achieved impressive novel view synthesis results with volume rendering techniques. Some latest efforts combine surface and volume rendering by expressing volume density as a function of the underlying 3D surface, which in turn improves scene geometry.
[Goal & future] The ultimate goal is to infer the underlying geometric structures and identify object and structure semantics, even from a partial, single view observation.
given a set of photographs of an object or a scene, estimate the most likely 3D shape that explains those photographs, under the assumptions of known materials, viewpoints, and lighting conditions.
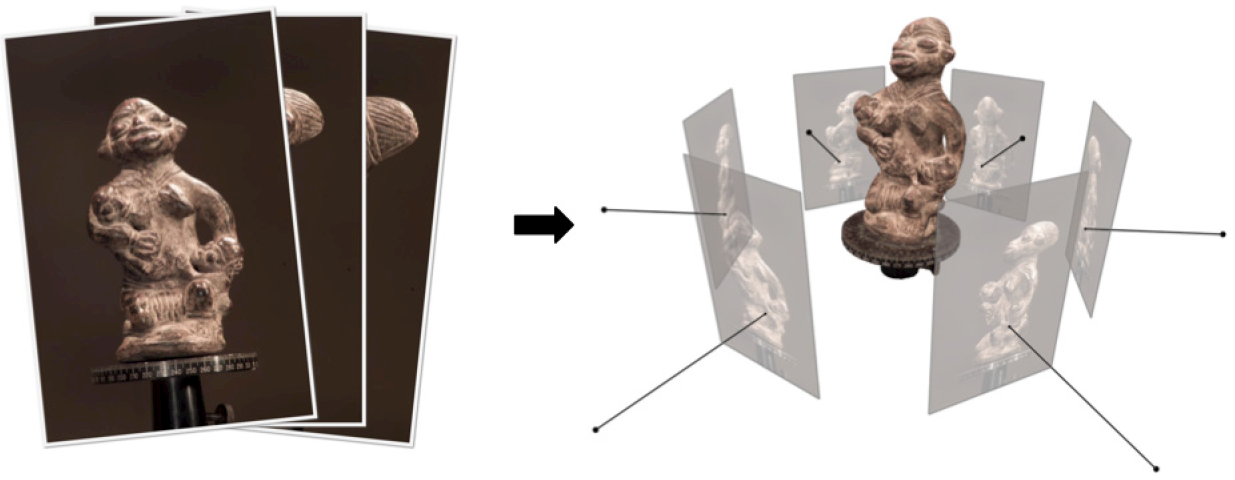
(figure from 'Multi-View Stereo: A tutorial')
Let
The function
The futher problem is recover a 3D shape with texture and mesh from a single view observation. This need utilize a pre-trained 3D GAN by searching for a latent space that best resembles the target mesh. As we all know that the pre-trained GAN encapsulates rich 3D semantics in terms of mesh geometry and texture, searching within the GAN manifold thus naturally regularizes the realness and fidelity of the reconstruction.
Click subfolders to see the rich literatures and details.
- Multi-View 3D Reconstruction
- Method: Multi-View Stereo (MVS)
- Method: 3D Representation
- Novel-View Synthesis (NVS)
- Single View Reconstruction
- 3D-Aware-Generation
- Predict Camera & Depth
- 3D Style-Transfer & Editing
- large and more complex scenes
- scenes captured from sparse viewpoints
- the core is ambiguities.
- 3D semantic reconstruction
- instance reconstruction
Thank you for your support.