4 ‐ Entendendo Índice, Shards e Segments no Elasticsearch
O Elasticsearch é um mecanismo de busca e análise distribuído que armazena dados em uma estrutura chamada "índice". Para entender como os dados são indexados e consultados no Elasticsearch, é crucial compreender os conceitos de índices, shards e segments.
Um índice no Elasticsearch é uma coleção de documentos que possuem características semelhantes. Por exemplo, você pode ter um índice para dados de clientes, outro para produtos, etc. Cada índice é identificado por um nome único e é onde os dados são armazenados e consultados.
Para distribuir e escalar dados horizontalmente, o Elasticsearch divide cada índice em partes menores chamadas "shards". Cada shard é, na verdade, um índice Lucene completo e independente. A divisão em shards permite que o Elasticsearch distribua dados e cargas de trabalho em vários nós, possibilitando o processamento paralelo e melhorando o desempenho e a disponibilidade.
- Primary Shards: Quando um índice é criado, o número de primary shards é definido e não pode ser alterado após a criação do índice.
- Replica Shards: Cada primary shard pode ter zero ou mais cópias, chamadas replica shards. Elas servem para proporcionar alta disponibilidade e failover, além de permitir distribuir as cargas de leitura.
Dentro de cada shard, os dados são armazenados em estruturas chamadas "segments". Um segment é um índice invertido imutável, que é a estrutura de dados central usada pelo Lucene para armazenamento e recuperação de dados. Quando novos documentos são indexados, eles são inicialmente escritos em um buffer na memória e, eventualmente, são escritos em um novo segmento no disco.
Com o tempo, para otimizar a leitura e economizar espaço, o Elasticsearch mescla periodicamente esses segmentos em segmentos maiores através de um processo chamado "segment merging".
-
Escrita: Quando um documento é indexado, ele é adicionado a um buffer de memória e, em seguida, escrito em um novo segmento no disco. Esse segmento é imutável, o que significa que, para atualizar ou deletar um documento, o Elasticsearch marca o documento antigo como deletado e adiciona uma versão atualizada em um novo segmento.
-
Busca: Durante uma operação de busca, o Elasticsearch consulta todos os segmentos relevantes (em todos os shards pertinentes) e, em seguida, consolida os resultados antes de retorná-los ao usuário.
-
Merge: Periodicamente, o Elasticsearch mescla segmentos pequenos em segmentos maiores para manter a eficiência na busca. Documentos marcados como deletados são removidos durante esse processo de merge.
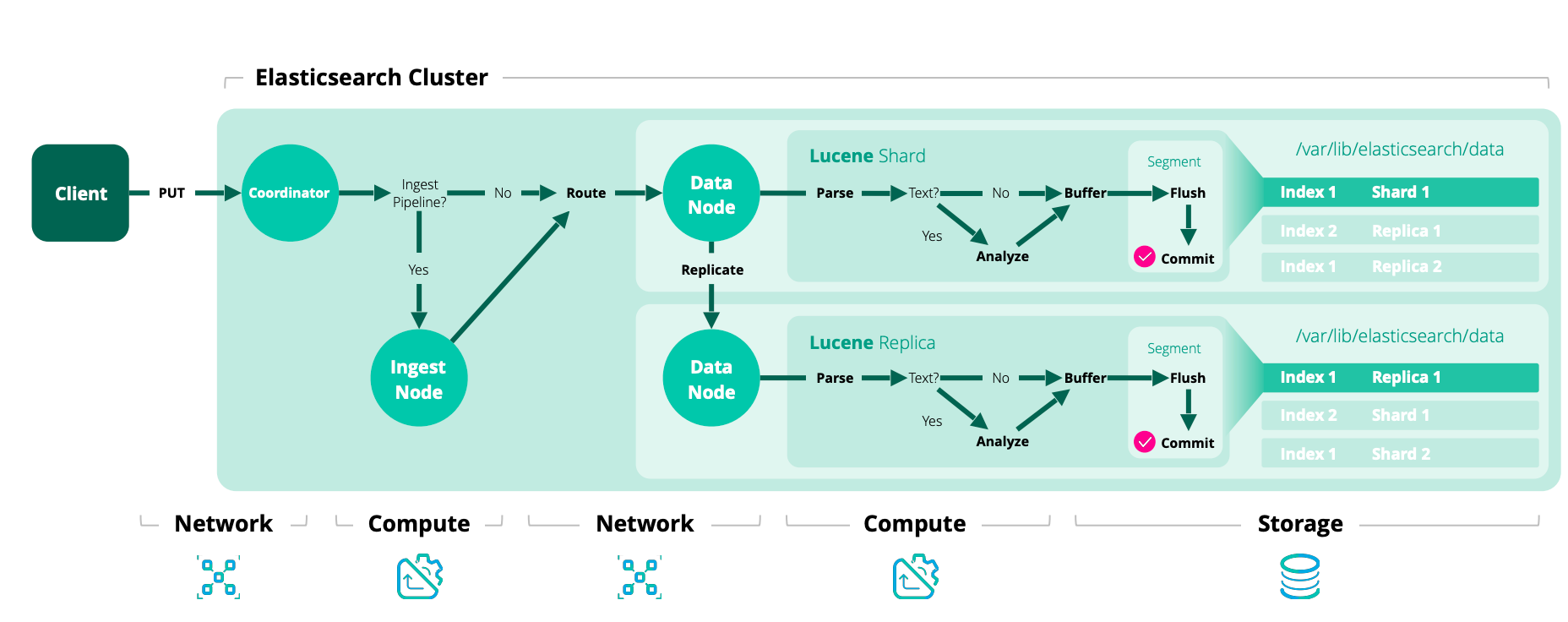
Fonte: Elasticsearch Blog
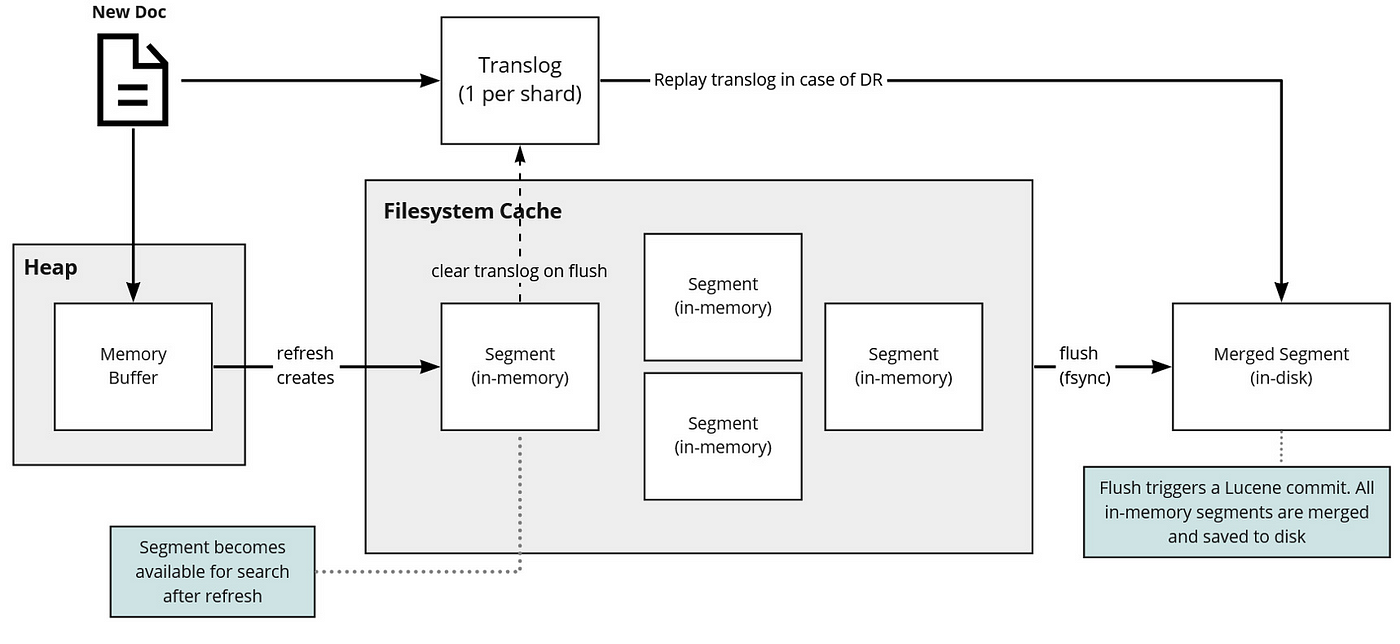
Fonte: Medium [Luis Sena]
Esse diagrama ilustra o processo de indexação, mostrando como os documentos são adicionados aos buffers de memória, escritos em segmentos e eventualmente mesclados.
Entender esses conceitos é fundamental para otimizar o Elasticsearch para diferentes cargas de trabalho, garantindo que a arquitetura escolhida esteja alinhada com os requisitos de desempenho, escalabilidade e disponibilidade do sistema.
A alocação e o roteamento de shards são aspectos cruciais para a eficiência e escalabilidade do Elasticsearch. Eles determinam como os shards são distribuídos pelos nós do cluster e como os dados são acessados durante as operações de busca e indexação.
O Elasticsearch oferece vários níveis de alocação de shards, permitindo um controle refinado sobre onde e como os dados são armazenados:
-
Alocação Baseada em filtro: Você pode controlar a alocação em nível de nódulo, especificando em quais nós os shards podem ser alocados, usando atributos como
_name,_ip,_hostou atributos personalizados definidos pelo usuário. -
Alocação Baseada em Atributos - Awareness: Permite definir regras de alocação com base em atributos personalizados atribuídos aos nós, como tipo de hardware, localização geográfica ou qualquer outra característica relevante.
-
Alocação Baseada em Disco: O Elasticsearch monitora o espaço em disco disponível em cada nó e pode realocar shards para equilibrar o uso do disco em todo o cluster, bem como evitar alocação em nós com pouco espaço disponível.
Esta arquitetura é uma estratégia de gerenciamento de dados que permite otimizar o custo e o desempenho no Elasticsearch, categorizando os dados e os nós em diferentes "temperaturas" com base na frequência de acesso e na necessidade de velocidade de recuperação:
-
Hot Nodes: Nós "quentes" são configurados com hardware de alto desempenho (como SSDs) e são usados para indexação e armazenamento de dados que são acessados frequentemente ou que estão sendo ativamente atualizados.
-
Warm Nodes: Nós "mornos" têm configurações de hardware menos potentes e são usados para dados que são acessados menos frequentemente, mas que ainda precisam estar prontamente disponíveis.
-
Cold Nodes: Nós "frios" armazenam dados que são raramente acessados, podendo ter discos de menor custo e menos recursos. A recuperação desses dados pode ser mais lenta.
-
Frozen Nodes: Introduzidos na versão 7.10 com o conceito de "searchable snapshots", os nós "congelados" permitem armazenar dados em sistemas de armazenamento de objetos baratos, como o Amazon S3. Os dados aqui são muito raramente acessados e as buscas são significativamente mais lentas.

Fonte: Opster - ILM: Manage the index lifecycle
- Otimização de Custos: Ao mover dados antigos ou raramente acessados para hardware mais barato, você reduz os custos operacionais.
- Desempenho Aprimorado: Alocar dados ativos em hardware de alto desempenho melhora a velocidade de indexação e busca.
- Escalabilidade: Facilita o escalonamento do cluster, pois você pode adicionar nós específicos para cada tipo de carga de trabalho.
- Gerenciamento de Dados: Facilita a implementação de políticas de gerenciamento do ciclo de vida dos dados (ILM - Index Lifecycle Management).
Utilizar essa arquitetura permite que organizações grandes e pequenas gerenciem seus dados de maneira eficaz, equilibrando custo e acesso em um ambiente altamente escalável e performático.
Este laboratório abordará como ajustar configurações de alocação de shards em vários níveis no Elasticsearch, incluindo a configuração de consciência de alocação de shards no arquivo elasticsearch.yml.
Desativar a alocação de shards:
PUT /_cluster/settings
{
"persistent": {
"cluster.routing.allocation.enable": "none"
}
}Esse comando impede a alocação de novos shards, útil durante a manutenção.
Reativar a alocação de shards:
PUT /_cluster/settings
{
"persistent": {
"cluster.routing.allocation.enable": "all"
}
}Ajustar limites de espaço em disco para alocação de shards:
PUT /_cluster/settings
{
"persistent": {
"cluster.routing.allocation.disk.watermark.low": "85%",
"cluster.routing.allocation.disk.watermark.high": "90%",
"cluster.routing.allocation.disk.watermark.flood_stage": "95%"
}
}Essas configurações ajudam a evitar problemas de espaço em disco ao alocar shards:
cluster.routing.allocation.disk.watermark.low: O cluster interrompe a alocação de shards nos nós que atingirem essa marca de uso de disco.
cluster.routing.allocation.disk.watermark.high: O cluster realoca shards de nós que atingirem essa marca para nós que estejam com menos uso de disco.
cluster.routing.allocation.disk.watermark.flood_stage: O cluster interrompe a indexação de dados (limite de indexação e recepção de dados).
É comum alterar essas configurações quando essas porcentagens refletem em mudanças significativas no uso do disco.
Configurar a consciência de alocação no elasticsearch.yml:
Para configurar a consciência de alocação, primeiro, você precisa adicionar atributos relevantes aos seus arquivos de configuração nos nós. Por exemplo, para usar o atributo datacenter, adicione o seguinte no elasticsearch.yml de cada nó:
node.attr.datacenter: datacenter1Ajuste o valor (datacenter1, datacenter2, etc.) conforme apropriado para cada nó.
Verificar os atributos aplicados:
GET _cat/nodeattrsEspera-se observar os atributos de datacenter aplicados para os 3 nós.
Aplicar configurações de consciência de alocação via API:
PUT /_cluster/settings
{
"persistent": {
"cluster.routing.allocation.awareness.attributes": "datacenter"
}
}Isso instrui o Elasticsearch a considerar o atributo datacenter na alocação de shards. O Elasticsearch irá equilibrar até onde for possível a alocação de shards entre os dois datacenters. Quando não for mais possível garantir a redundância, ele aloca os shards restantes em um dos dois datacenters (mesmo sem redundância).
Forçar a consciência de alocação:
PUT /_cluster/settings
{
"persistent": {
"cluster.routing.allocation.awareness.force.datacenter.values": "datacenter1,datacenter2"
}
}Isso garante que os shards sejam equilibrados entre os datacenters especificados. Caso não seja possível equilibrar, o Elastic opta por deixar o shard réplica não alocado em nenhum nó (unassigned).
Exemplo de filtragem de alocação:
Obs: Desfazer as configurações de awareness antes de executar essa atividade
PUT /_cluster/settings
{
"persistent": {
"cluster.routing.allocation.awareness.force.datacenter.values": null,
"cluster.routing.allocation.awareness.attributes": null
}
}PUT /_cluster/settings
{
"persistent": {
"cluster.routing.allocation.exclude._host": "node3",
"cluster.routing.allocation.exclude._name": "node3",
"cluster.routing.allocation.exclude.datacenter": "datacenter2"
}
}Essas configurações direcionam o cluster para evitar a alocação para o node3, como pode ser verificado através do comando abaixo:
GET _cat/allocation?vObs.: Desfazer as configurações na sequência:
PUT /_cluster/settings
{
"persistent": {
"cluster.routing.allocation.exclude._host": null,
"cluster.routing.allocation.exclude._name": null,
"cluster.routing.allocation.exclude.datacenter": null
}
}Ao configurar o arquivo elasticsearch.yml em cada nó e usar a API do Elasticsearch, você pode controlar de forma granular onde e como os shards são alocados, otimizando o desempenho e a resiliência do cluster.
Este laboratório detalha a configuração de um cluster Elasticsearch com três nós, denominados elastic-instancia1, elastic-instancia2 e elastic-instancia3, respectivamente configurados para as camadas hot, warm e cold. Também são apresentadas as instruções para iniciar e parar cada instância usando comandos específicos.
-
Configurando
elastic-instancia1como Hot:Edite o arquivo
elasticsearch.ymlnaelastic-instancia1:node.roles: [master, data_content, ingest, data_hot]
Parar a instância:
pkill -F pid
Iniciar a instância:
./bin/elasticsearch -p pid -d
-
Configurando
elastic-instancia2como Warm:Atualize o
elasticsearch.ymlnaelastic-instancia2:node.roles: [master, data_content, ingest, data_warm]
Parar a instância:
pkill -F pid
Iniciar a instância:
./bin/elasticsearch -p pid -d
-
Configurando
elastic-instancia3como Cold:Modifique o
elasticsearch.ymlnaelastic-instancia3:node.roles: [master, data_content, ingest, data_cold]
Parar a instância:
pkill -F pid
Iniciar a instância:
./bin/elasticsearch -p pid -d
Após configurar os arquivos elasticsearch.yml, reinicie cada instância do Elasticsearch para aplicar as mudanças.
-
Criação de um Índice no Nó Hot:
Para criar um índice e alocá-lo diretamente no nó hot, utilize:
PUT /hot_index { "settings": { "index.routing.allocation.include._tier_preference": "data_hot" } }
O índice será criado e alocado no nó configurado para a camada hot.
-
Transição de Índice para Warm:
Para simular a transição de um índice do hot para warm:
PUT /hot_index/_settings { "settings": { "index.routing.allocation.include._tier_preference": "data_warm" } }
Para verificar onde estão os shards desse índice execute o comando:
GET _cat/shards/hot_indexIsso modificará a preferência de alocação do índice para a camada warm.
-
Transição de Índice para Cold:
De forma semelhante, para mover um índice para a camada cold:
PUT /hot_index/_settings { "settings": { "index.routing.allocation.include._tier_preference": "data_cold" } }
Para verificar onde estão os shards desse índice execute o comando:
GET _cat/shards/hot_indexAgora, o índice será realocado para o nó configurado como cold.
Ao final do laboratório, comentar o parâmetro node.roles no arquivo elasticsearch.yml das 3 instâncias do cluster, e reiniciá-las.
-
Edite o arquivo
elasticsearch.ymlnaelastic-instancia1:cd /opt/elastic/elastic-instancia1 vi config/elasticsearch.yml#node.roles: [master, data_content, ingest, data_hot]Parar a instância:
pkill -F pid
Iniciar a instância:
./bin/elasticsearch -p pid -d
-
Edite o arquivo
elasticsearch.ymlnaelastic-instancia2:cd /opt/elastic/elastic-instancia2 vi config/elasticsearch.yml#node.roles: [master, data_content, ingest, data_warm]Parar a instância:
pkill -F pid
Iniciar a instância:
./bin/elasticsearch -p pid -d
-
Edite o arquivo
elasticsearch.ymlnaelastic-instancia3:cd /opt/elastic/elastic-instancia3 vi config/elasticsearch.yml#node.roles: [master, data_content, ingest, data_cold]Parar a instância:
pkill -F pid
Iniciar a instância:
./bin/elasticsearch -p pid -d
A utilização do parâmetro node.role facilita a configuração de cada nó para um papel específico dentro da arquitetura hot-warm-cold, permitindo uma gestão de dados mais eficaz e otimizada no cluster Elasticsearch.