7 ‐ Ingestão de Dados no Elasticsearch
A ingestão de dados é um aspecto crucial do uso do Elasticsearch, permitindo que você colete, enriqueça, transforme e indexe seus dados de várias fontes. Várias ferramentas podem ser usadas para esse fim, cada uma com suas particularidades: Ingest Pipelines, Beats, Elastic Agent e Logstash.

O Ingest Pipeline é um recurso do Elasticsearch que permite definir uma série de processadores que transformam, enriquecem ou manipulam dados antes de serem indexados. Esses pipelines são executados no momento da indexação, diretamente no nó do Elasticsearch, proporcionando uma maneira conveniente e eficiente de pré-processar os dados.
- Funcionalidades: Pode incluir a remoção de campos desnecessários, conversão de formatos de data, extração de partes de strings, entre outras transformações.
- Aplicabilidade: Ideal para transformações leves e quando não se necessita de um processamento externo complexo.
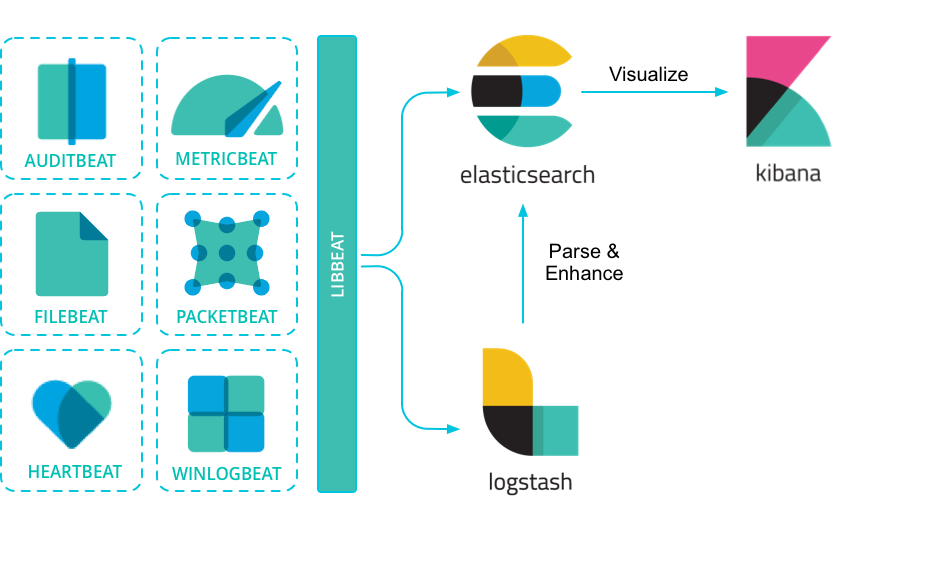
Beats são agentes leves de envio de dados que são instalados nas máquinas para coletar dados e enviá-los diretamente para o Elasticsearch ou para o Logstash para processamento adicional. Existem vários Beats para diferentes propósitos, como Filebeat para logs, Metricbeat para métricas, Packetbeat para tráfego de rede, etc.
- Funcionalidades: Cada Beat é projetado para uma fonte de dados específica, coletando dados e metadados relevantes.
- Aplicabilidade: Útil quando você deseja coletar dados diretamente das fontes sem transformações complexas.
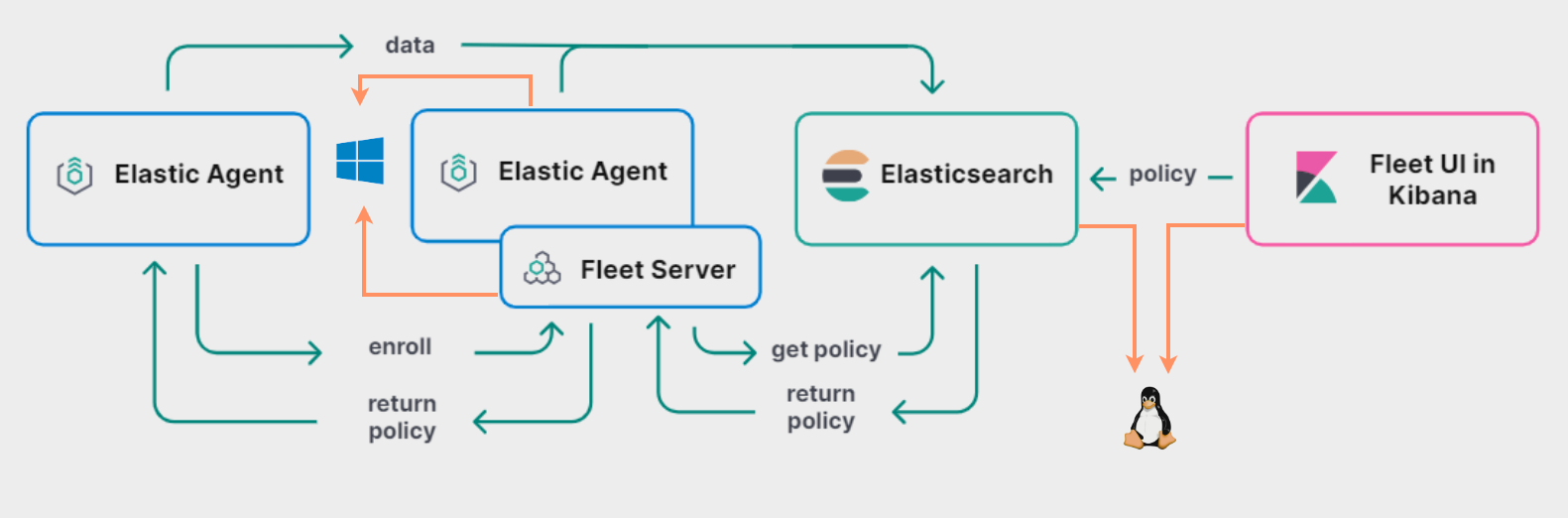
O Elastic Agent é uma ferramenta mais recente e unificada para observabilidade e segurança, podendo gerenciar vários Beats e integrar-se com o Fleet para gerenciamento centralizado. O Elastic Agent simplifica a coleta, transformação e envio de dados para o cluster do Elasticsearch.
- Funcionalidades: Oferece uma maneira unificada de implantar e gerenciar a coleta de dados em sua infraestrutura, podendo substituir o uso de múltiplos Beats.
- Aplicabilidade: Ideal para cenários onde é necessário uma solução de ingestão e gestão mais holística e integrada.
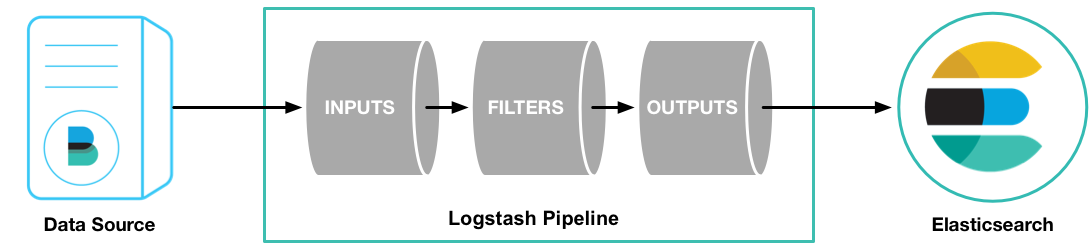
Logstash é uma ferramenta robusta de ingestão de dados que pode coletar, transformar e enviar dados para o Elasticsearch. Diferentemente dos Beats, o Logstash oferece uma ampla variedade de plugins de entrada, filtros e saídas, permitindo processamentos mais complexos e transformações de dados.
- Funcionalidades: Pode filtrar, analisar e transformar dados de diversas formas, com uma vasta gama de plugins disponíveis.
- Aplicabilidade: Recomendado para situações em que é necessário um processamento de dados mais complexo ou quando se trabalha com uma variedade mais ampla de fontes de dados.
- Beats e Elastic Agent: Direcionados para a coleta rápida e eficiente de dados de várias fontes, com o Elastic Agent oferecendo uma abordagem mais unificada e gerenciável.
- Logstash e Ingest Pipelines: Enquanto o Logstash é adequado para processamentos mais pesados e complexos, os Ingest Pipelines oferecem uma solução mais leve e direta dentro do próprio Elasticsearch.
- Integração: Todos esses componentes podem ser combinados de várias maneiras, dependendo dos requisitos específicos de ingestão, processamento e análise de dados.
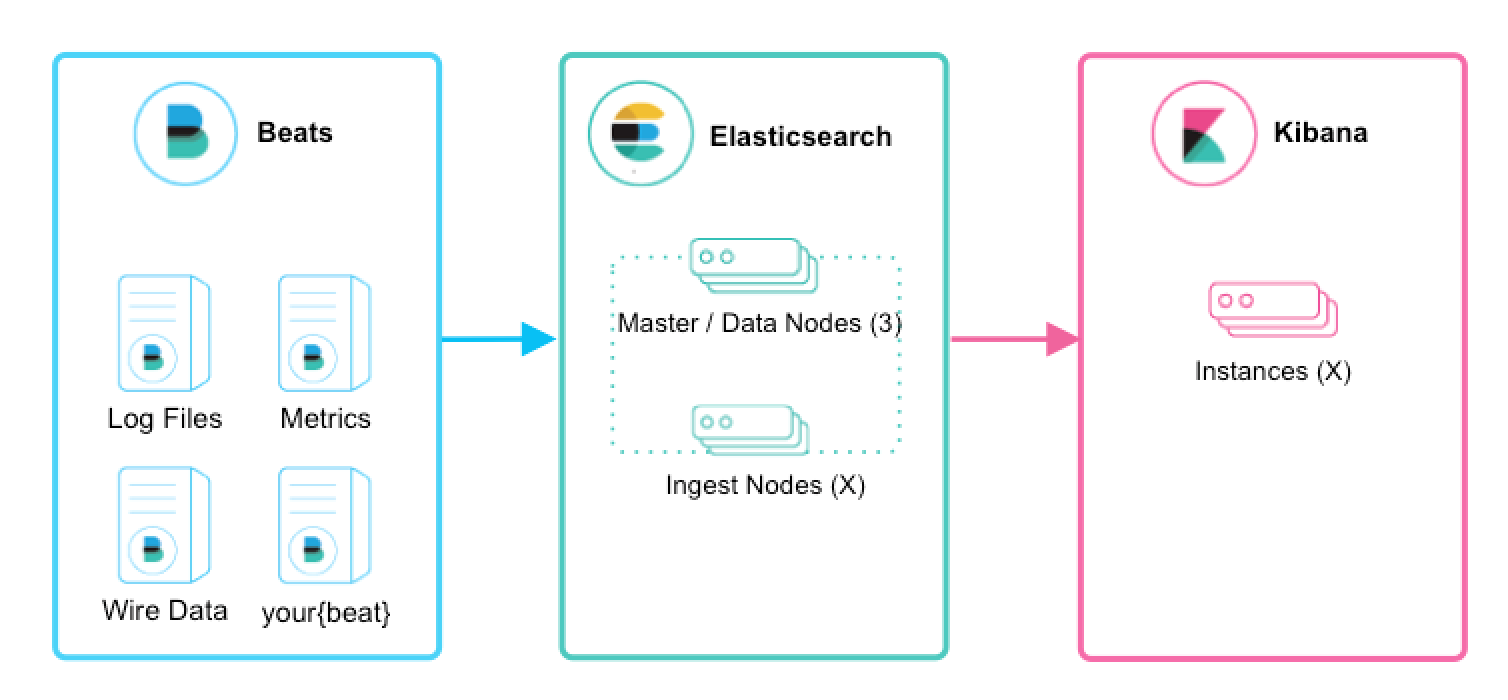
Possíveis arquiteturas:

Neste laboratório, você aprenderá a instalar, configurar e utilizar o Filebeat e o Metricbeat no Linux Ubuntu, incluindo a configuração para a coleta de logs do sistema e logs do Tomcat, além de métricas do sistema. Também cobriremos o uso do Keystore para proteger informações sensíveis como senhas.
-
Instale o Filebeat:
cd /opt/elastic/ curl -L -O https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-8.12.1-amd64.deb sudo dpkg -i filebeat-8.12.1-amd64.deb -
Instale o Metricbeat:
cd /opt/elastic/ curl -L -O https://artifacts.elastic.co/downloads/beats/metricbeat/metricbeat-8.12.1-amd64.deb sudo dpkg -i metricbeat-8.12.1-amd64.deb
-
Crie e configure o Keystore para o Filebeat:
sudo filebeat keystore create sudo filebeat keystore add ES_PASSWORD
No prompt, será solicitada a criação de uma senha para ser armazenada. Neste caso, vamos armazenar a senha de autenticação do usuário elastic. Após a criação, é possível verificar a keystore criada através do comando:
ls /var/lib/filebeat/
-
Crie e configure o Keystore para o Metricbeat:
sudo metricbeat keystore create sudo metricbeat keystore add ES_PASSWORD
No prompt, será solicitada a criação de uma senha para ser armazenada. Neste caso, vamos armazenar a senha de autenticação do usuário elastic. Após a criação, é possível verificar a keystore criada através do comando:
ls /var/lib/metricbeat/
-
Configure o Filebeat para coletar logs do sistema:
-
Habilite o módulo system:
sudo filebeat modules enable system -
Habilite a coleta do módulo conforme exemplo aaixo:
vi /etc/filebeat/modules.d/system.yml - module: system # Syslog syslog: enabled: true auth: enabled: true
-
Atualize a configuração do filebeat.yml
setup.kibana: host: "https://localhost:5601" ssl.verification_mode: "none" output.elasticsearch: hosts: ["localhost:9200","localhost:9201","localhost:9202"] preset: balanced protocol: "https" username: "elastic" password: "${ES_PASSWORD}" ssl.verification_mode: "none"
-
-
Configure o Metricbeat para coletar métricas do sistema:
-
Habilite o módulo system:
cd /opt/elastic/ sudo metricbeat modules enable system
-
Atualize a configuração em
/etc/metricbeat/metricbeat.yml:setup.kibana: host: "https://localhost:5601" ssl.verification_mode: "none" output.elasticsearch: hosts: ["localhost:9200","localhost:9201","localhost:9202"] preset: balanced protocol: "https" username: "elastic" password: "${ES_PASSWORD}" ssl.verification_mode: "none"
-
-
Teste as configurações e a conectividade:
-
Filebeat:
sudo filebeat test config sudo filebeat test output
-
Metricbeat:
sudo metricbeat test config sudo metricbeat test modules sudo metricbeat test output
-
-
Execute o setup inicial para carregar dashboards Kibana, index templates e ingest pipelines:
-
Filebeat:
sudo filebeat setup
-
Metricbeat:
sudo metricbeat setup
-
-
Inicie os serviços:
sudo systemctl start filebeat sudo systemctl start metricbeat
Após completar esses passos, você terá o Filebeat configurado para coletar logs do sistema e do Tomcat, utilizando o recurso de multiline para logs do Tomcat, e o Metricbeat configurado para coletar métricas do sistema. Ambos os serviços estão seguramente configurados para comunicar com o Elasticsearch, usando senhas armazenadas no Keystore.
Ao final do laboratório, parar os serviços do filebeat e metricbeat, para evitar conflitos com os próximos laboratórios:
sudo systemctl stop filebeat
sudo systemctl stop metricbeatNeste laboratório, você aprenderá a instalar e configurar o Elastic Agent e o Fleet Server no Linux Ubuntu. O Elastic Agent é uma ferramenta unificada para coleta de dados que pode ser gerenciada centralmente pelo Kibana usando o Fleet. Vamos configurar o Elastic Agent para coletar logs e métricas do sistema. Para isso siga os passos abaixo:
- Configurando o Fleet Server
Inicialmente acesse o menu e vá para o Menu>Stack Management>Fleet.

Agora clique em no botão Add Fleet Server

Preencha os campos conforme modelo abaixo. Não esqueça que o endereço ip deve estar acessível pelos agentes e com o https no endereço ok?

Após definido o endereço ip, o Fleet irá instalar a Policy conforme figura abaixo:

Agora ele fornece um passo a passo de como instar o Elastic Agent para que o o Fleet Server fique disponível. Siga os passo abaixo:
Observação importante:
Logar com o usuário root:
su - root
# No prompt, será solicitada a senha do usuário de acesso à máquina
Durante a instalação o Elastic Agent irá perguntar se ele será um serviço do Linux e nesse caso digite "Y" para conforme que Sim:
Após instalação o Elastic Agent irá estabelecer a conexão com o Elasticsearch e validar as configurações. A tela abaixo deverá ser apresentada confirmado que o Elatic Agent e o Fleet Server está configurado e funcional:

Após feito a confirmação podemos voltar a tela do Fleet no qual podemos constatar que o Elastic Agent está ativo e configurado com a policy Fleet Server.

Neste tópico, vamos explorar como indexar dados de um banco de dados SQLite no Elasticsearch usando o Logstash. Vamos seguir um passo a passo para preparar o ambiente, configurar o Logstash e finalmente indexar os dados.
-
Instalação do SQLite:
Como root, instale o SQLite no Ubuntu:
sudo apt-get update sudo apt-get install sqlite3
-
Criação da Pasta Datasets:
Mude para o usuário
elastice crie a pastadatasetsem/opt/elastic:sudo -u elastic mkdir -p /opt/elastic/datasets
-
Download do Banco de Dados de Exemplo:
Baixe o banco de dados SQLite de exemplo para a pasta
/opt/elastic/datasets:sudo -u elastic wget -P /opt/elastic/datasets https://raw.githubusercontent.com/tornis/esstackenterprise/master/datasets/chinook.db
-
Download do Driver JDBC do SQLite:
Baixe o driver JDBC do SQLite para a pasta
/opt/elastic/datasets:sudo -u elastic wget -P /opt/elastic/datasets https://github.com/tornis/esstackenterprise/raw/master/datasets/sqlite-jdbc-3.7.2.jar
-
Download e Descompactação do Logstash:
Baixe e descompacte o Logstash:
sudo -u elastic wget -P /opt/elastic https://artifacts.elastic.co/downloads/logstash/logstash-8.12.1-linux-x86_64.tar.gz cd /opt/elastic sudo -u elastic tar -xzf logstash-8.12.1-linux-x86_64.tar.gz mv logstash-8.12.1 logstash cd logstash
Após preparar o ambiente, vamos configurar o pipeline do Logstash para indexar os dados no Elasticsearch.
-
Criação do Arquivo de Configuração:
Crie o arquivo
config/database.confno diretório do Logstash com o seguinte conteúdo:sudo -u elastic vi config/database.conf
input { jdbc { jdbc_driver_library => "/opt/elastic/datasets/sqlite-jdbc-3.7.2.jar" jdbc_driver_class => "org.sqlite.JDBC" jdbc_connection_string => "jdbc:sqlite:/opt/elastic/datasets/chinook.db" jdbc_user => "" schedule => "* * * * *" tracking_column => "invoicedate" tracking_column_type => "timestamp" use_column_value => true statement => "SELECT * from Customer c JOIN Invoice i on i.CustomerId = c.CustomerId WHERE i.InvoiceDate > :sql_last_value ORDER BY i.InvoiceDate ASC limit 5" } } filter { date { match => [ "invoicedate", "yyyy-MM-dd HH:mm:ss" ] } } output { elasticsearch { hosts => ["https://localhost:9200","https://localhost:9201","https://localhost:9202"] ssl_enabled => true ssl_verification_mode => "none" index => "chinook-%{+YYYY.MM.dd}" user => "elastic" password => "123456" } }Explicação:
-
input/jdbc: Define a configuração para coletar dados do banco SQLite usando JDBC.
-
jdbc_driver_library: Caminho para o driver JDBC do SQLite. -
jdbc_driver_class: Classe do driver JDBC. -
jdbc_connection_string: String de conexão com o banco de dados. -
jdbc_user: Nome do usuário para conexão (vazio para SQLite). -
schedule: Cronograma para executar a consulta. -
tracking_column: Coluna usada para rastrear as últimas alterações. -
statement: Consulta SQL para coletar dados.
-
-
filter/date: Configura o filtro para analisar o campo de data.
-
output/elasticsearch: Define como os dados serão enviados para o Elasticsearch.
-
hosts: Endereços dos nós do Elasticsearch. -
ssl_enabledessl_verification_mode: Configurações para o uso de SSL. -
index: Padrão de nomeação do índice no Elasticsearch. -
userepassword: Credenciais para o Elasticsearch.
-
-
Para ajustar o Logstash para carregar a configuração específica do arquivo database.conf, precisamos editar o arquivo pipelines.yml, que gerencia múltiplos pipelines dentro do Logstash. Veja como proceder:
-
Editar o Arquivo
pipelines.yml:No diretório de instalação do Logstash, edite ou crie o arquivo
pipelines.yml. Especifique o caminho do arquivo de configuraçãodatabase.conf:cd /opt/elastic/logstash sudo -u elastic vi config/pipelines.yml- pipeline.id: chinook_pipeline path.config: "/opt/elastic/logstash/config/database.conf"
Aqui,
pipeline.idé um identificador único para o pipeline, epath.configaponta para o arquivo de configuração que acabamos de criar.
Após configurar o arquivo pipelines.yml, podemos iniciar o Logstash para processar os dados conforme definido.
-
Iniciar o Logstash:
Navegue até o diretório do Logstash e execute o seguinte comando para iniciar o processo de ingestão:
sudo -u elastic /opt/elastic/logstash/bin/logstash
Esse comando inicia o Logstash e carrega a configuração especificada, iniciando a coleta de dados do banco de dados SQLite e indexando-os no Elasticsearch.
Ao executar esses passos, o Logstash irá periodicamente consultar o banco de dados SQLite conforme definido na consulta SQL em database.conf, e indexar os resultados no Elasticsearch. Você pode verificar o sucesso da operação observando os logs do Logstash e também verificando se os dados aparecem no índice especificado no Elasticsearch.
Neste laboratório, vamos explorar o Logstash como uma alternativa de indexação de arquivos CSV. A interface do Kibana oferece a opção de subir arquivos diretamente do browser, no entanto, o limite do tamanho desses arquivos é 100MB. O Logstash é um caminho prático e de fácil manuseio para ler esses arquivos, aplicar transformações, se necessário, e indexar no Elasticsearch, por exemplo.
O Dataset foi instalado nas máquinas, uma vez que, pelo seu tamanho, não seria possível importá-lo de um repositório do GitHub. Assim, o primeiro passo será mover ele do diretório temporário para a pasta datasets:
mv /tmp/kaggle_sample.csv /opt/elastic/datasets/-
Criação do template do índice:
Antes de realizarmos a indexação do dataset, vamos criar um mapeamento para os campos dessa base, de forma que o Elastic mapeie da forma correta os campos, otimizando armazenamento e garantindo performance nas buscas.
Acesse o DevTools do Kibana, e envie a requisição de criação do template do índice
air_quality:PUT air_quality { "mappings": { "properties": { "id_station": { "type": "keyword" }, "indicator_code": { "type": "keyword" }, "indicator_name": { "type": "text", "fields": { "keyword": { "type": "keyword" } } }, "indicator_dimension": { "type": "keyword" }, "value": { "type": "float" }, "datetime": { "type": "date" }, "source": { "type": "keyword" } } } }
-
Criação do Centralized Pipeline Management:
Vamos habilitar a gestão centralizada dos pipelines do Logstash através do Kibana. O Elastic oferece essa opção para que não seja necessária a interrupção e restart do Logstash quando se fizer necessária a adição de um novo pipeline no seu fluxo. Para configurarmos isso, é necessário fazer o apontamento do cluster Elastic nas configurações do Logstash.
Edite o arquivo
config/logstash.ymlno diretório do Logstash com o seguinte conteúdo:xpack.management.enabled: true xpack.management.pipeline.id: ["*"] xpack.management.elasticsearch.username: "elastic" xpack.management.elasticsearch.password: "123456" xpack.management.elasticsearch.hosts: ["https://localhost:9200", "https://localhost:9201", "https://localhost:9202"] xpack.management.elasticsearch.ssl.verification_mode: "none"
Aqui, estamos configurando o nosso cluster Elastic para ser o orquestrador dos pipelines criados, e estamos adicionando um
wildcardno id dos pipelines, de forma que ele aceite qualquer novo nome de pipeline de agora em diante. -
Iniciar o Logstash:
Navegue até o diretório do Logstash e execute o seguinte comando para iniciar o serviço:
sudo -u elastic /opt/elastic/logstash/bin/logstash
Após o seu início, ele irá considerar apenas os pipelines que forem configurados diretamente da interface do Kibana. Uma vez que não temos nenhum pipeline configurado lá, você deve observar nos logs do Logstash algumas mensagens de erro, indicando que até o momento ele não encontrou um pipeline para iniciar:

-
Criação do arquivo de configuração:
Agora, a criação dos pipelines será toda feita no Kibana. Acesse o Menu > Stack Management > Logstash Pipelines e crie um novo pipeline:

No seu ID, coloque o nome referenciador
air_quality_pipeline. No espaço do pipeline, apague o exemplo que consta e cole o seguinte conteúdo:input { file { path => "/opt/elastic/datasets/kaggle_sample.csv" start_position => "beginning" sincedb_path => "/dev/null" } } filter { csv { separator => "," skip_header => "true" columns => [ "id_station", "indicator_code", "indicator_name", "indicator_dimension", "value", "datetime", "source" ] } mutate { convert => { "value" => "float" } remove_field => ["log","host","event","message","@version"] } date { match => ["datetime", "YYYY-MM-DD HH:mm:ss"] target => "datetime" } } output { elasticsearch { hosts => ["https://localhost:9200","https://localhost:9201","https://localhost:9202"] ssl_enabled => true ssl_verification_mode => "none" index => "air_quality" user => "elastic" password => "123456" } }Explicação:
-
input/file: Define a configuração para coletar dados de algum arquivo local.
-
path: Especifica o caminho do arquivo ou arquivos que o Logstash deve monitorar e ler. O caminho pode incluir curingas para ler múltiplos arquivos ou diretórios. -
start_position: Define a posição inicial de leitura do arquivo quando ele é encontrado pela primeira vez. Pode serbeginning(início) ouend(final). -
sincedb_path: Especifica o caminho para o arquivosincedb, que armazena o estado de leitura do arquivo. Isso permite que o Logstash continue de onde parou após uma reinicialização ou interrupção.
-
-
filter: Configura o filtro para analisar os campos com necessidade de transformação.
-
csv: Interpreta e processa dados de arquivos CSV. -
mutate: Permite diversas transformações nos campos de dados. -
date: Analisa e converte campos de data/hora para o formato de tempo padrão do Elasticsearch.
-
-
output/elasticsearch: Define como os dados serão enviados para o Elasticsearch.
-
hosts: Endereços dos nós do Elasticsearch. -
ssl_enabledessl_verification_mode: Configurações para o uso de SSL. -
index: Padrão de nomeação do índice no Elasticsearch. -
userepassword: Credenciais para o Elasticsearch.
-
Pelo Kibana, também é possível definir configurações do pipeline em questão:

Após todas as configurações apontadas, clique no botão "Create and deploy". Nesse momento, o Logstash vai receber aquele pipeline e, se seu ID corresponder ao padrão definido no parâmetro
xpack.management.pipeline.iddeclarado no arquivologstash.yml, o Logstash irá iniciar o pipeline criado. -
Nesta seção, exploraremos uma outra abordagem de ingestão e tratamento de dados: os Ingest Pipelines. Uma distinção importante dos Ingest Pipelines em relação ao Logstash e aos Beats é que eles não buscam ativamente os dados para tratamento; em vez disso, os Ingest Pipelines recebem e processam as informações diretamente.
Esta técnica oferece uma maneira eficiente de realizar transformações e preparações nos dados antes de serem indexados no Elasticsearch. Ao compreender e utilizar os Ingest Pipelines, podemos otimizar o fluxo de dados e garantir que estejam prontos para serem consultados e analisados de forma eficaz.
No Kibana, abra o menu principal e clique em Stack Management > Ingest Pipelines. Para criar um pipeline, clique em Create Pipeline > New Pipeline. Também é possível usar as APIs de ingestão no Dev Tools para criar e gerenciar pipelines. Sempre importante lembrar que os processors definidos são executados sequencialmente na ordem especificada.

Antes de usar um pipeline em produção, é recomendado que você teste ele utilizando documentos de amostra. Ao criar ou editar um pipeline no Kibana, clique em "Add documents". Na aba Documents, forneça documentos de amostra e clique em "Run the pipeline". Da mesma forma, o Dev Tools também permite testar pipelines usando a API de simulação de pipeline. Você pode especificar um pipeline configurado no caminho da solicitação.
PUT _ingest/pipeline/meu_pipeline
{
"processors": [
{
"set": {
"field": "idade",
"value": "40"
}
},
{
"dissect": {
"field": "classificacao",
"pattern": "%{fornecedor_status} %{fornecedor_negativado} %{fornecedor_ativo_receita}"
}
},
{
"html_strip": {
"field": "descricao_fornecedor"
}
}
]
}
- Para cada documento:
POST fornecedor/_doc/3?pipeline=meu_pipeline
{
"codigo": 124,
"nome_fornecedor": "GOL Linhas Aereas",
"cnpj": "12222334000102",
"endereco": "Rua tal e etc",
"bairro": "Fulano",
"cidade": "Caxias",
"uf": "RJ",
"classificacao": "sim não ativo",
"descricao_fornecedor": "<br>teste de remoçao html</br>"
}- Para o índice:
PUT fornecedor_teste
{
"settings": {
"default_pipeline": "meu_pipeline"
}
}POST fornecedor_teste/_doc/1
{
"codigo": 124,
"nome_fornecedor": "GOL Linhas Aereas",
"cnpj": "12222334000102",
"endereco": "Rua tal e etc",
"bairro": "Fulano",
"cidade": "Caxias",
"uf": "RJ",
"classificacao": "sim não ativo",
"descricao_fornecedor": "<br>teste de remoçao html</br>"
}-
Criar o índice:
PUT informacoes_pessoas { "mappings": { "properties": { "nome": { "type": "text" }, "idade": { "type": "integer" }, "sexo": { "type": "keyword" }, "ddd": { "type": "keyword" }, "numero_telefone": { "type": "keyword" }, "uf": { "type": "keyword" } } } }
-
Indexar documentos:
POST _bulk {"index": {"_index": "informacoes_pessoas", "_id": 1}} {"nome": "Ana Silva", "idade": 28, "sexo": "F", "ddd": "11", "numero_telefone": "912345678", "uf": "SP"} {"index": {"_index": "informacoes_pessoas", "_id": 2}} {"nome": "Bruno Pereira", "idade": 35, "sexo": "M", "ddd": "21", "numero_telefone": "923456789", "uf": "RJ"} {"index": {"_index": "informacoes_pessoas", "_id": 3}} {"nome": "Carlos Almeida", "idade": 42, "sexo": "M", "ddd": "31", "numero_telefone": "934567890", "uf": "MG"} {"index": {"_index": "informacoes_pessoas", "_id": 4}} {"nome": "Daniela Costa", "idade": 29, "sexo": "F", "ddd": "41", "numero_telefone": "945678901", "uf": "PR"} {"index": {"_index": "informacoes_pessoas", "_id": 5}} {"nome": "Eduardo Lima", "idade": 33, "sexo": "M", "ddd": "51", "numero_telefone": "956789012", "uf": "RS"} {"index": {"_index": "informacoes_pessoas", "_id": 6}} {"nome": "Fernanda Souza", "idade": 26, "sexo": "F", "ddd": "61", "numero_telefone": "967890123", "uf": "DF"} {"index": {"_index": "informacoes_pessoas", "_id": 7}} {"nome": "Gabriel Oliveira", "idade": 39, "sexo": "M", "ddd": "71", "numero_telefone": "978901234", "uf": "BA"} {"index": {"_index": "informacoes_pessoas", "_id": 8}} {"nome": "Helena Martins", "idade": 31, "sexo": "F", "ddd": "81", "numero_telefone": "989012345", "uf": "PE"} {"index": {"_index": "informacoes_pessoas", "_id": 9}} {"nome": "Igor Santos", "idade": 37, "sexo": "M", "ddd": "91", "numero_telefone": "990123456", "uf": "PA"} {"index": {"_index": "informacoes_pessoas", "_id": 10}} {"nome": "Juliana Ramos", "idade": 25, "sexo": "F", "ddd": "65", "numero_telefone": "901234567", "uf": "MT"}
GET informacoes_pessoas/_search -
Criar Ingest Pipeline:
PUT _ingest/pipeline/numero_completo_pipeline { "description": "Pipeline para combinar DDD e número de telefone em um único campo", "processors": [ { "script": { "source": "ctx.numero_completo = ctx.ddd + ctx.numero_telefone" } } ] }
-
Atualizar índice:
POST informacoes_pessoas/_update_by_query?pipeline=numero_completo_pipelineGET informacoes_pessoas/_search