Databases And SQL
Database is the main way of persisting data. Why can't we just use a file? File is good for simple data or where performance is not an issue. But usually, data has some structure and we need speed for both looking it up and adding new records. If we were to use files, with growing size the performance would downgrade significantly and operations, that take miliseconds would take hours to complete.
The classical and most popular database is SQL. It groups data into class-like structures- tables. A single row in a table represents a single record (or object in OOP). Db is more than just tables, it also includes: *stored procedures and functions (similar to OOP methods), indexes (for speed, similar to hashes in hasmap) and more depending on a database.
In this lesson we will learn the basics of database design and the language to communicate with it- SQL.
Over the years, there have been many companies which wanted to fine-tune SQL to their needs. Due to that, a lot of different SQL dialects have come to light. For example, there are: MSSQL, MySQL, PostgreSQL, MariaDb, Cassandra...
When using basic SQL queries, you probably won't even notice a difference. But when you go into details and use very specific features of a db provider, you will notice that one provider has something that others don't and vice versa. When you are just starting out to learn SQL, don't worry about it.
For learning purpose we will be using SQLite- a local database mostly used in Android devices for local storage. It's open source, free to use and easy to setup.
Table is made of rows and columns. Rows are like objects, columns are like fields in OOP. Column has a type, value, you can also add validation to it (not null, > 100, unique, etc). Following best practices, a row should be identified by a single key- called a Primary Key. Row might also refer to other tables- this is done using those tables primary key. In the context of a table that references another table through a key, that key is called Foreign Key.
For example. People table:
| Id | Name | Birthday | AddressId |
|---|---|---|---|
| 1 | Thomas Jenkins | 2004-08-08 | 1 |
| 2 | Robin Atkinson | 1976-03-22 | 4 |
| 3 | Shokugana Shana | 1994-11-14 | 2 |
| 4 | Gabriel of Xena | 1002-05-11 | 3 |
And Addresses table:
| Id | Country | City | Street | House |
|---|---|---|---|---|
| 3 | JP | Tokya | Swedbni | 5 |
| 2 | LTU | Zegzdriai | Kondroto | 11 |
| 1 | UK | London | Barclays | 24 |
| 4 | GR | Athens | Asu | 77 |
We won't go into detail of different types a column could be. If needed, you can easilly look it up yourself.
When designing a table the key things to remember are these:
- Split tables, so that there is little to no duplicate data.
- Single id column for easy identification. For example, instead of using first and last name of a person- use their personal id as an identifier.
- Single table should refer to a single entity. For example, if the same table contain dog name, age, person name, person age- it should be split to two.
- Don't allow columns where you can deduce information. For example, if you have a row with Tokyo, then you can tell for sure the country- Japan. So a city would be enough, based on that you can find its' country.
- Consider amount of elements in a table. If it can be very big, use
bigintoverint. - If you plan to merge database, consider using
UID(GUID) as an id.
If you want to find out more about databases best practices, look up "databases normalization forms".
SQL is the language of database. Using it we can do everything inside of a database:
- Create new databases
- Create, delete, edit new tables
- Add, remove, update rows
- Get rows
- React to actions done to rows
- Do validation for rows that are being inserted
- ...
The most common operations of data persistence are called CRUD. They are:
- Create
- Read
- Update
- Delete
In the examples here we will be using the same two tables above: People and Addresses.
Adding a new row to a table is done using using an INSERT INTO statement:
INSERT INTO TableName (columns) VALUE (values)Adding a new person in People table can be done
INSERT INTO People (Id, Name, Email) VALUES (1,'Tomas Kleinauskas', '[email protected]')The key thing to remember is to add values in the same order as you wrote columns.
It's worth noting, that if an id column is flagged as seeded, we won't have to (in fact we won't be able to) provide an id column. Seeded id columns is usually the way to go because it's rare to care about a very specific id for a new entity, unless that id has some domain meaning.
Getting data from a table is done using
SELECT columns FROM tableFor example, get all people:
SELECT * FROM People* symbol is used for getting all the columns in that table.
If we wanted to get just names and emails of people, we could:
SELECT Name, Email FROM People*Where is used for filtering data. It's similar to an if statement because it requires to be followed by a logical condition.
For example:
SELECT * FROM People
WHERE email = '[email protected]'This returns all the columns of people of that people. Please note that we use single quotes ('') for giving a value of an email. There is no double quotes in SQL and that's the way of defining a string.
It's often required to do a pattern-matching lookup that matches some but not all of the text. For example, get all people with @gmail.com email:
SELECT * FROM People
WHERE email LIKE '%@gmail.com'UPDATE statement is used for updating table rows.
UPDATE Table SET Column1 = Value1, Column2 = Value2For example, update email of Tomas Kleinauskas:
UPDATE People
SET Email = '[email protected]'
WHERE Name = 'Tomas Kleinauskas'DELETE is a statement used for removing a row from a table:
DELETE FROM Table
WHERE conditionFor example, delete person of Id 1:
DELETE FROM People
WHERE Id = 1DELETE and UPDATE are two risky operations, because they change a state and there is no way of undoing it. Therefore, if you are not sure what the impact of DELETE or UPDATE is, first do a SELECT statement to see which records will be affected.
JOIN is a statement used to join columns from two tables. This is how from a reference through Id we can get the linked date:
SELECT Table1.Name, Table2.Country
FROM Table1
SOME_JOIN Table2
ON Table1.Table2Id = Table2.IdThere are two most common joins:
INNER JOIN joins columns of two tables, but only if the connection between the two tables exists. For example get people and the countries they live in:
SELECT People.Name, Addresses.Countries
FROM People
INNER JOIN Addresses
ON People.AddressId = Addresses.IdIf some people did not have an address, we would not return them.
LEFT JOIN joins columns of two tables regardless of the link between the two tables missing in some cases. Let's get people and countries once again:
SELECT People.Name, Addresses.Countries
FROM People
LEFT JOIN Addresses
ON People.AddressId = Addresses.IdThis time if a person has no address- they will be returned. but with a null country.
Union should not be confused with a join. Union also involves two tables, but instead of adding extra columns, it merely adds extra rows. In other words, it takes two tables and expects the same columns in each, adding rows from the two to a resulting table.
For example, if we had a tables: Items(Name), Merchandises(Name), we could get all the names of Items and Merchandises by running the following:
SELECT Name FROM Merchandises
UNION
SELECT Name FROM ItemsIt's worth mentioning that duplicate values will not be duplicated. For example if the same name exists both in items and merchandises, it will be returned once.
As mentioned before, a db might have primary and foreign keys. Flagging a column as a key is a matter of modifying its properties.
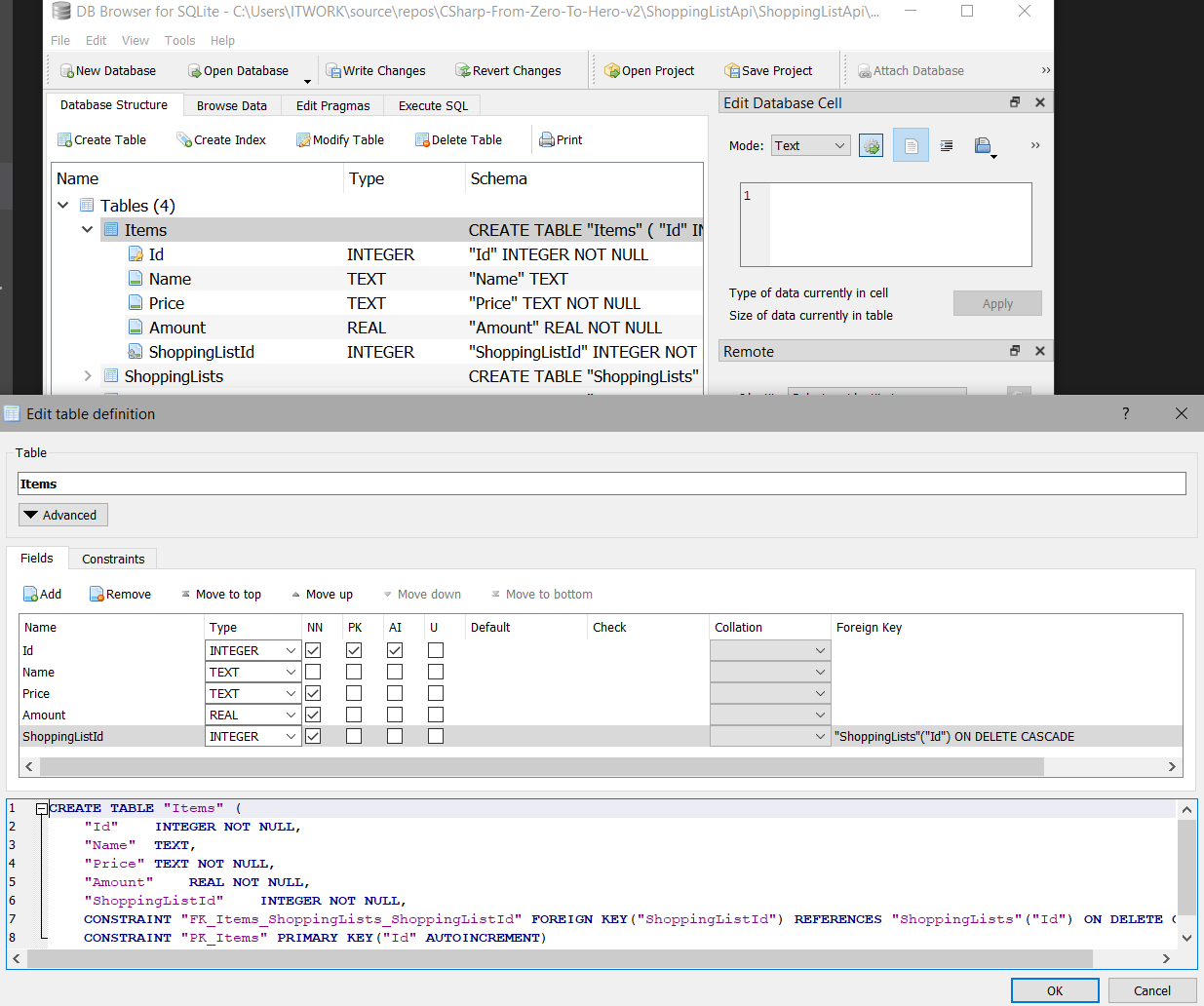
In the picture above you can see both the GUI and the resulting SQL- of how to apply key properties. In the FK column you can see the reference to another table. Below in SQL you can see Contraint.. Foreign Key.. References...
Please note that the exact way of adding constraints like primary and foreign keys are subject for different DB providers and tooling.
Next to a foreign key constraint we have ON DELETE CASCADE. This means that if parent entity (the one which references another) is deleted, the child entity will be deleted as well not leaving any loose ends that way.
It's worth mentioning that big databases often need grouping between tables. Such grouping is called a schema. Schema is really like a namespace, grouping multiple tables under a single starting prefix. For example, a big db might have two schemas: product and hr. And so the tables will need to be called through schemaname.tablename, for example:
-product.items
-product.factories
-product.suppliers
-hr.people
-hr.absences
-hr.employees
Comments in SQL are written using double dash: --.
For example:
-- SELECT nothing FROM People will get ignored :)In a relational (SQL) database, two tables can be related in 3 different ways.
When a private key of one table is also a foreign key to another- we have a 1:1 relation (reads one to one). It's a rare one and usually such a relationship is simply merged as a single table.
1:1 in OOP usually refers to inheritance. For example Person can also be an employee.
When a table refers to another via a foreign key, it makes a 1:n relation (reads one to many). This means that many rows on a referenced table will have a connection with a single row on a table that references it through a foreign key.
For example, in a library, a person can borrow multiple books but a single book can be borrowed by a single person at a time. Here Person:Book make a 1:n relation.
1:n is the most common kind of relation and we normally strive to turn all other relationships into this one.
When both tables cross-reference each other we have a n:m (reads many to many) relation. This means that two tables have foreign keys to each other.
This is always a bad idea and is fixed used an in-between table.
An example for this relation could be authors and books. A book can have many authors and the same author can write many books.
Bad:
Book: Id, Name, AuthorId
Author: Id, Name, BookId
To properly solve this relation we will need 3 tables:
Book: Id, Name
BookAuthor: BookId, AuthorId
Author: Id, Name
When you want to get all the books with their authors, you will join all 3 tables: Book, Author and BookAuthor. BookId, AuthorId in BookAuthor are a composite key.
Using the in-between table, we reduced n:m relation to 2 1:n relations.
Last lesson we learned that EF can generate a database from C# models. Today we will learn how to do the opposite- generate models from an existing database.
If you don't have it already, install a NuGet package:
dotnet add package Microsoft.EntityFrameworkCore.tools Run the following:
dotnet ef dbcontext scaffold "connection-string" provider... -o "your/models/path" Sometimes you might need to provide a project as well, this can be done using --project argument. In our case the command for ShoppingListApi will look like this:
dotnet ef dbcontext scaffold "DataSource=ShoppingList.db" Microsoft.EntityFrameworkCore.Sqlite -o "Db/Generated" --project ShoppingListApiThis will try to connect to a database of connection string DataSource=ShoppingList.db using provider Microsoft.EntityFrameworkCore.Sqlite and generate models at Db/Generated folder.
- What is SQL?
- What is a table, row, column, stored procedure?
- What are the most common db data types for ID columns?
- What is CRUD?
- How to get all elements from a single table?
- How to get some elements from 2 tables?
- How to simplify complex table or column names in a SELECT?
- What's the difference between a UNION and a JOIN?
- How to run raw SQL without using an ORM in C#?
- What's the difference between INNER and LEFT JOINs?
- Why is UPDATE and DELETE two dangerous commands?
- How to know which elements of a DELETE or UPDATE commands will be affected?
- How many keys can a table have?
- How to link one table with another?
- Can you insert two rows with the same key in the same table?
- How to solve a problem of many:many relationship?
You're tasked with implementing a school database. There are many many classes with many students in them (student can belong to a single class at a time). A single class has a schedule per each day which repeats periodically. Schedule include start time, day and subject teacher. Subject teacher can teahc a single subject, but a single subject can have many teachers.
Design a database base on this description. Use Db-First approach and apply EF to get all students with their schedules.