Iteration 12 Architecture
This wiki page describes the architecture for Iteration 12 of the SCOOP project.
The architecture context is basically the same as the previous iteration. However, we will be using physical machines for deployment.

This iteration will run in a live clinic setting for the gateway, and a laboratory environment for the hub.
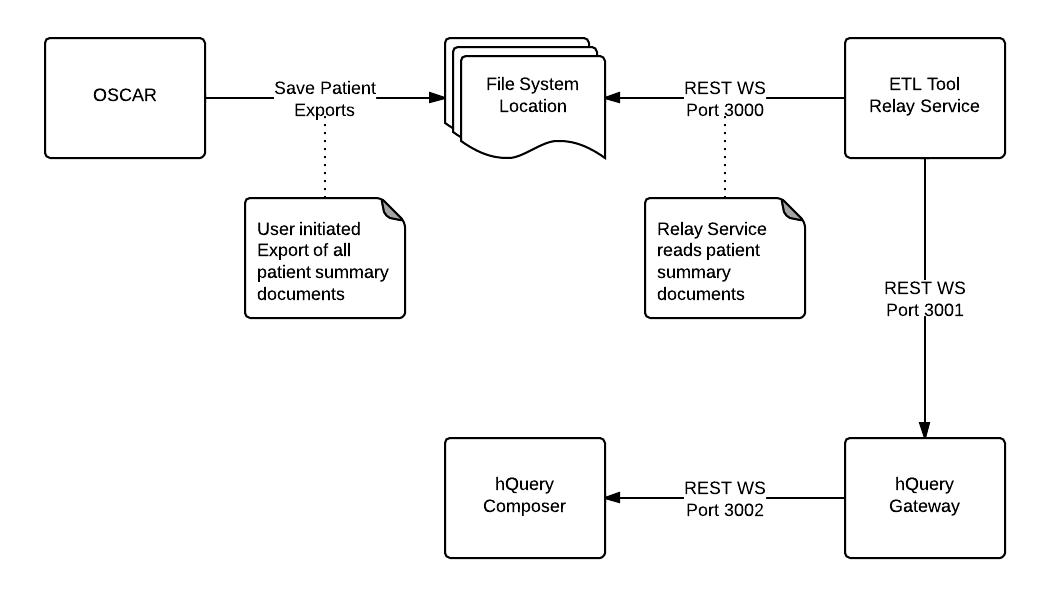
1. We are continuing to enhance and refactor OSCAR to export the patient summary document, either for a single individual or by batch for all individuals with a record in the EMR.
2. The middleware A lightweight OSCAR instance containing a scheduled job event which will generate E2E only updated records and immediately relay them to the local gateway via REST POST.
3. hQuery Hub will be investigated as to how we can extend the reporting functionality of the resultant queries. This will allow for future iterations to have a more meaningful result for the researcher by providing a better view of the information.
Privacy Individual information never leaves the practice. Early feedback from discussions with the faculty physicians UBC highlighted their stewardship of patient information as a serious matter. There’s a genuine concern that anonymous data collected may be used for unintended research purposes in the future. Several are concerned by the risks of data aggregation, even when the data is de-identified.
Open Source As SCOOP development is sponsored with public funds it will be released as open source for anyone to use. In addition, SCOOP will only rely on free, open source components so that its use is accessible to any individual/group.
OSCAR In addition to being open source, OSCAR is the EMR used by many UBC clinical faculty and physicians. A few of these faculty members will be the initial SCOOP users. For this reason, OSCAR will be the first supported EMR.
Software design of the export feature in OSCAR
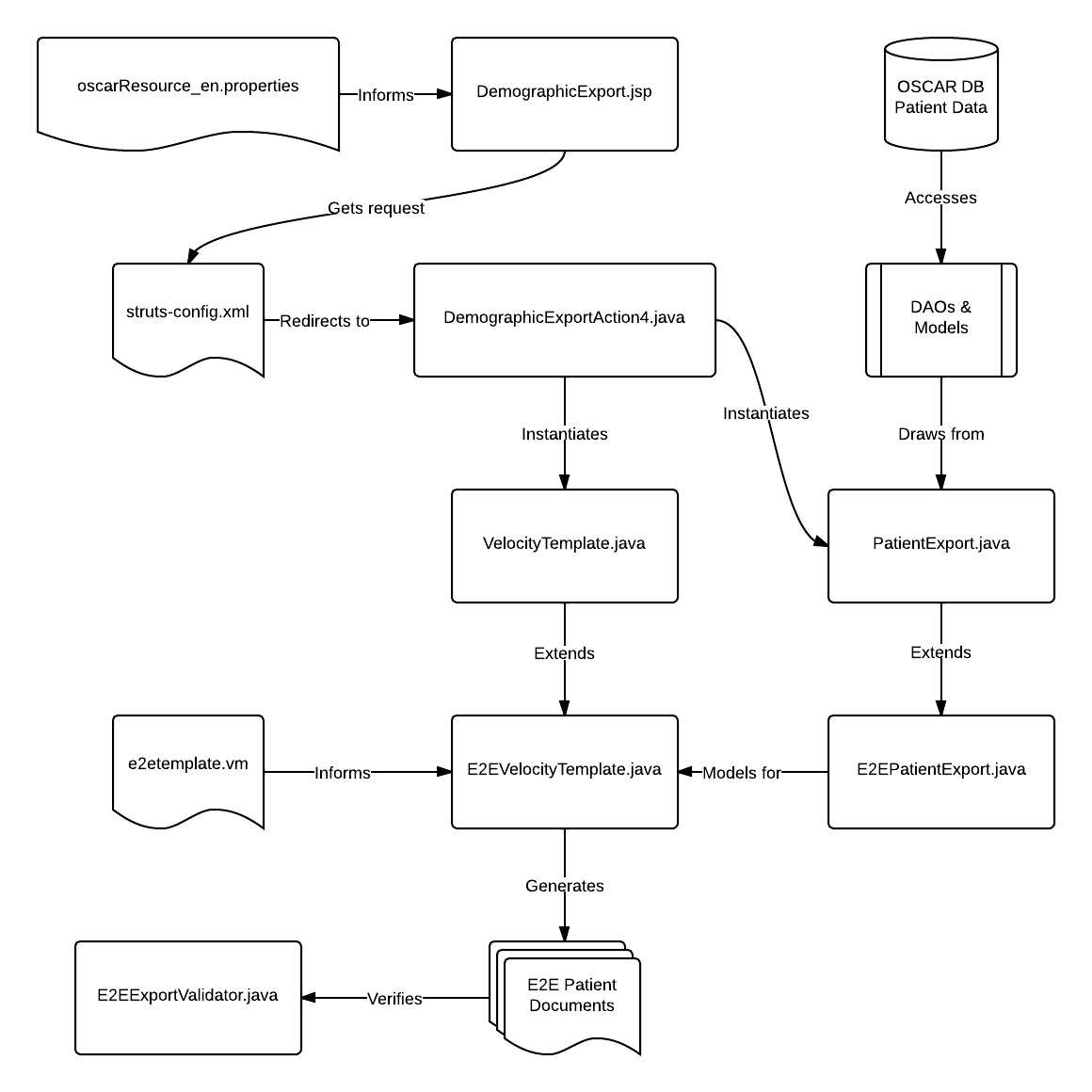
We will attempt to stay true to the MVC design. Velocity based templating requires both a template and a data model. We have the PatientExport object draw on all the pre-existing DAOs and models and have it group up the relevant fields for easy velocity access. Most of the heavy code work will be found in e2etemplate.vm, and DemographicExportAction4.java acts as the Event Handler and file management for the export function on the front-end. There is a scheduled job written to automatically generate and send reports in the back-end.
Software design for new hQuery enhancements
HTTPS will be used for the front-end access of the hQuery composer/hub. Communication between the composer and gateway will be HTTP but shall be protected via a reverse SSH tunnel.
Query Design
Since hQuery follows the map-reduce paradigm for gathering and returning results, we will also be using a mapping and reducing design. It is expected that all previous queries will still be able to function correctly.
We expect all previous queries to function correctly. As the query sets will draw from a wide range of supported data types, no queries are expected to fail.
The list of queries in the query set can be found on github here.
Since our reduction function works for a wide range of inputs, it will remain the same as previous iterations.
function reduce(key, values) {
var result = 0;
while (values.hasNext()) {
result += values.next();
}
return result;
}Introduction to E2E E2E, or EMR to EMR, is a CDA specification being developed by BC's PITO organization. Its main purpose is to create a standard in which EMR data can be transmitted to other Canadian EMRs in a standardized way.
Overview of E2E sections The E2E sections can be found in the EMR-2-EMR (E2E) page of the wiki.
Scope of content for Iteration 12 In order to sufficiently return value back to the OSCAR community, we need to implement a compliant E2E conversion standard exporter. As such, our scope includes all sections and content that is defined as required by the E2E EMR Conversion specification.
OSCAR An Open Source EMR system used by many private physicians. This is way that individual information is captured - and the user interface for the physician practioner end user.
hQuery Gateway The query gateway is a web based application that provides the back end for executing queries. The query gateway which exposes a query API, accepts queries, runs those queries against the patient data, and returns the results of the query back to the query composer.
hQuery Composer The query composer is a web based application that provides the front end for creating, managing, and executing queries. Those queries are executed against the query gateway which exposes a query API, accepts queries, runs those queries against the patient data, and returns the results of the query back to the query composer.
Scoop Endpoint refers to all the non-EMR SCOOP software components that will reside at a practice in the future. This includes the hQuery Gateway and relay-service.rb.
SCOOP Hub This is the application that the researcher uses to ask a "question" of the Research Network. This includes features for query management, policy enforcement, privacy management, and security. Currently, hQuery composer is the only software system in the hub - but more design and enhancements are needed.
SCOOP is licensed under a Creative Commons Attribution-ShareAlike 3.0 Unported License.
